Welcome to Dan’s brain

The contents of my head are not useful if they stay in there, so I have copy-pasted the main good bits onto the internet, right here.
Here you can find everything on the site, making no distinction between half-finished notebooks and ephemeral, complete blog posts.
Themes: whatever shiny thing distracted me and needed notes taken, including but not limited to
- interesting problems in statistical inference,
- tedious technicalities in solving said interesting problems,
- survival tips, broadly construed, for wherever I am living, and
- philosophy of each of the above things.
Not what you are looking for? You might be after information about me, or my other projects.
Finding it hard to keep track of? I am experimenting with an email subscription. Beta test it by clicking the button:
This front page is slow to load right now. Sorry about that; I’m working on it.

Attention Deficit (Hyperactivity) Disorder
gene
health
learning
mind
neuron
utility

Editing images
computers are awful
generative art
making things
photon choreography

Editing images using a GUI
computers are awful
generative art
making things
photon choreography

Quarto integrated website system
academe
faster pussycat
how do science
javascript
julia
language
making things
plain text
premature optimization
python
R
writing

The property market is pollution
cooperation
culture
economics
housing
incentive mechanisms
institutions
insurgency
making things
policy
spatial
straya
wonk
Algorithmic statistics
compsci
information
pseudorandomness
statistics
statmech
stringology

Guesstimation
computers are awful
faster pussycat
number crunching
office
Monte Carlo
UI

Internet search engines
computers are awful together
faster pussycat
information provenance
NLP
search

Git tricks
computers are awful
information provenance
workflow

Git GUIs
computers are awful
information provenance
UI
workflow

Syncthing
computers are awful
computers are awful together
concurrency hell
distributed
diy
P2P

Optimisation
functional analysis
optimization
statmech

Adaptive design of experiments
functional analysis
how do science
model selection
optimization
statmech
surrogate

An orderly retreat from relevance
agents
bounded compute
collective knowledge
distributed
economics
edge computing
extended self
faster pussycat
incentive mechanisms
innovation
language
machine learning
mind
neural nets
NLP
technology
unsupervised

Scientific institutions and mechanisms
adaptive
bounded compute
collective knowledge
distributed
economics
how do science
incentive mechanisms
institutions
learning
mind
networks
sociology
standards
swarm
Neural likelihood inference
approximation
Bayes
feature construction
likelihood free
machine learning
measure
metrics
probability
sciml
statistics
time series
Ethical consumption
economics
ethics
networks
wonk
South-east Asia
place
VS Code online and networked
computers are awful together
faster pussycat
plain text
UI
workflow
Decentralized net services
computers are awful together
concurrency hell
confidentiality
distributed
diy
game theory
P2P

Bayesian posterior inference via optimisation
Bayes
estimator distribution
Markov processes
Monte Carlo
probabilistic algorithms
probability
Sufficiently good hedonism
bounded compute
economics
making things
money
utility

Urbanism
buzzword
cooperation
culture
design
diy
economics
housing
incentive mechanisms
institutions
insurgency
making things
policy
spatial
straya
the rather superior sort of city
wonk

Squared neural families
functional analysis
probability
statistics

Contemporary epidemiology of mental health
crisis
culture
economics
ethics
health
incentive mechanisms
mind
networks
rhetoric
snarks
sociology
wonk
virality

(Kernelized) Stein variational gradient descent
approximation
Bayes
functional analysis
Markov processes
measure
metrics
Monte Carlo
optimization
probabilistic algorithms
probability
statistics

Score matching
approximation
Bayes
Bregman
generative
Monte Carlo
neural nets
optimization
probabilistic algorithms
probability
statistics

Designing less toxic social media
confidentiality
democracy
distributed
diy
economics
evolution
game theory
insurgency
networks
P2P
wonk

Bayes linear methods
Bayes
Gaussian
generative
Hilbert space
how do science
linear algebra
measure
Monte Carlo
statistics

Presentation tools
academe
communicating
computers are awful
faster pussycat
office
photon choreography
standards
Jupyter front end systems
faster pussycat
premature optimization
python

Research discovery
academe
collective knowledge
faster pussycat
how do science
institutions
mind
networks
sociology
wonk

Hardware for neural networks
compsci
computers are awful
concurrency hell
grammar
number crunching
stringology
Variational message-passing algorithms in graphical models
algebra
approximation
Bayes
distributed
dynamical systems
generative
graphical models
machine learning
networks
optimization
probability
signal processing
state space models
statistics
stochastic processes
swarm
time series

TikZ/PGFplots etx
communicating
computers are awful
dataviz
faster pussycat
LaTeX
photon choreography
plain text
typography
UI
workflow

Designing social movements
agents
collective knowledge
cooperation
culture
democracy
distributed
economics
game theory
incentive mechanisms
institutions
insurgency
mind
networks
policy
rhetoric
social graph
sociology
swarm
wonk
Particle variational message passing
approximation
Bayes
distributed
dynamical systems
ensemble
generative
graphical models
machine learning
Monte Carlo
networks
optimization
probabilistic algorithms
probability
sciml
signal processing
state space models
statistics
stochastic processes
swarm
time series

Unconferences
academe
collective knowledge
how do science
information provenance
workflow

Morality and computational constraints
economics
mind
sociology

Gradient steps to an ecology of mind
adaptive
collective knowledge
cooperation
culture
economics
energy
evolution
extended self
game theory
gene
incentive mechanisms
learning
mind
networks
probability
social graph
sociology
statistics
statmech
utility
wonk

Python debugging, profiling and testing
computers are awful
premature optimization
python

Python packaging, dependency management and isolation
computers are awful
python
standards

Quasi-gradients of discrete parameters
calculus
classification
probabilistic algorithms
optimization
probability
statistics

Doubly robust learning for causal inference
algebra
graphical models
hidden variables
hierarchical models
how do science
machine learning
networks
neural nets
probability
statistics

Money, Australian-style
diy
economics
money
utility

Microstressors
boring
cooperation
culture
democracy
economics
ethics
language
mind
rhetoric
snarks
sociology
wonk

Superstimuli
adaptive
bounded compute
collective knowledge
cooperation
culture
economics
ethics
evolution
gene
incentive mechanisms
institutions
neuron
utility
wonk

Addiction
ethics
fit
health
learning
mind
neuron
utility

Learning curves
culture
economics
faster pussycat
institutions
mind
networks
standards
technology
Matrix algebra
algebra
calculus
functional analysis
linear algebra
optimization


Economics of large language models
agents
bounded compute
collective knowledge
concurrency hell
distributed
economics
edge computing
extended self
faster pussycat
incentive mechanisms
innovation
language
machine learning
neural nets
NLP
swarm
technology
UI
AI supremacy
economics
faster pussycat
innovation
language
machine learning
mind
neural nets
NLP
technology

Causal inference in highly parameterized ML
algebra
graphical models
hidden variables
hierarchical models
how do science
machine learning
networks
neural nets
probability
statistics

Stein’s method
approximation
functional analysis
measure
metrics
model selection
optimization
probability
spheres
statistics

Recurrent / convolutional / state-space
Bayes
convolution
dynamical systems
functional analysis
linear algebra
machine learning
making things
music
networks
neural nets
nonparametric
probability
signal processing
sparser than thou
state space models
statistics
time series

Differentiable learning of automata
compsci
machine learning
making things
neural nets

Generative art with language+diffusion models
buzzword
computers are awful
generative art
machine learning
making things
music
neural nets
photon choreography

Dynamic causality
algebra
graphical models
how do science
machine learning
networks
neural nets
probability
statistics

Cryptographic tokens, distributed ledgers, and blockchain-like-things
computers are awful
confidentiality
distributed
game theory
incentive mechanisms
money
Which are your 100 bytes?
economics
faster pussycat
innovation
language
machine learning
mind
neural nets
NLP
technology
UI

Simulation-based inference
approximation
Bayes
feature construction
likelihood free
machine learning
measure
metrics
probability
sciml
statistics
time series
Comment systems for static websites
computers are awful together
diy
doing internet
faster pussycat
plain text
UI
workflow

Let’s try substack
academe
faster pussycat
how do science
plain text
workflow
writing

China
place

Email blogs and newsletters
academe
faster pussycat
how do science
plain text
workflow
writing
Maximum Mean Discrepancy, Hilbert-Schmidt Independence Criterion
approximation
functional analysis
Hilbert space
measure
metrics
nonparametric
optimization
probability
statistics

Scalable vector graphics
computers are awful
faster pussycat
photon choreography

Graphical model / machine learning decoder ring
algebra
graphical models
hidden variables
hierarchical models
how do science
machine learning
networks
neural nets
probability
statistics

Procedurally generated diagrams
communicating
computers are awful
dataviz
faster pussycat
photon choreography
plain text
typography
UI
workflow

Quarto
academe
faster pussycat
how do science
javascript
julia
language
making things
plain text
premature optimization
python
R
writing

The robot regency
agents
bounded compute
collective knowledge
distributed
economics
edge computing
extended self
faster pussycat
incentive mechanisms
innovation
language
machine learning
mind
neural nets
NLP
technology
unsupervised

Money
diy
economics
money
utility

Nostr
computers are awful together
confidentiality
distributed
diy
economics
P2P

Factor graphs
algebra
graphical models
machine learning
networks
probability
statistics
Algorithmic mechanism design
economics
faster pussycat
game theory
incentive mechanisms
institutions
networks

Institutional alignment problems
cooperation
culture
economics
extended self
faster pussycat
game theory
incentive mechanisms
institutions
networks
swarm
wonk
Morphogenesis
agents
compsci
distributed
extended self
game theory
generative art
hidden variables
incentive mechanisms
life
photon choreography
self similar
spatial
statmech
swarm

Bureaucracy
cooperation
culture
economics
game theory
institutions
rhetoric
wonk

Cooperation in evolutionary context
adaptive
cooperation
culture
economics
evolution
gene
incentive mechanisms
wonk

Conflict theorist models of coordination
adaptive
bounded compute
cooperation
culture
economics
evolution
game theory
incentive mechanisms
networks
wonk

Dunning-Kruger theory of mind
bounded compute
cooperation
culture
how do science
incentive mechanisms
learning
mind
snarks
wonk

Intimate question systems
adaptive
bounded compute
cooperation
culture
ethics
evolution
extended self
gene
institutions
learning
mind
wonk

Battlers
cooperation
culture
economics
ethics
evolution
incentive mechanisms
mind
social graph
utility
wonk

ssh
computers are awful
computers are awful together
confidentiality
encryption

Terminal session management and multiplexing
computers are awful
faster pussycat
plain text
POSIX

submitit
computers are awful
computers are awful together
concurrency hell
distributed
premature optimization

Social organisation of knowledge
adaptive
agents
bounded compute
collective knowledge
distributed
economics
game theory
how do science
incentive mechanisms
institutions
learning
mind
networks
sociology
squad
standards
swarm

Drugs, prescribed
chemistry
health
mind
neuron

Data summarization
approximation
estimator distribution
functional analysis
information
linear algebra
model selection
optimization
probabilistic algorithms
probability
signal processing
sparser than thou
statistics

The money laundry
computers are awful together
confidentiality
cooperation
cryptography
economics
hand wringing
money
wonk

Australia in data
data sets
place
straya

Typst
academe
faster pussycat
how do science
plain text
workflow
Innovation
economics
innovation
intellectual property
making things
policy
sociology
spatial
technology
the rather superior sort of city

Status
cooperation
culture
economics
evolution
incentive mechanisms
mind
social graph
utility
wonk

Tensorboard
computers are awful
faster pussycat
how do science
information provenance
premature optimization

Tracking experiments in data science
computers are awful
faster pussycat
how do science
information provenance
premature optimization
LaTeX
computers are awful
faster pussycat
LaTeX
plain text
typography
UI
workflow

Ethnomusicology
culture
information provenance
making things
music
Symbols and the public sphere
cooperation
culture
democracy
distributed
economics
game theory
language
making things
mind
networks
rhetoric
semantics
sociology
virality
wonk

Linear algebra
algebra
functional analysis
Hilbert space
linear algebra

VS Code for python
computers are awful
faster pussycat
plain text
python
UI
workflow
![]()
Nearly-low-rank Hermitian matrices
feature construction
functional analysis
high d
linear algebra
networks
probability
signal processing
sparser than thou
statistics

The simplest thing
culture
economics
faster pussycat
institutions
mind
networks
standards

Mass power generation, engineering and use
ecology
economics
physics
snarks
spatial
statmech
technology

DIY social networks and groupware
computers are awful together
confidentiality
distributed
diy
economics
P2P
Privacy while web browsing
computers are awful
computers are awful together
confidentiality

Hyperparameter optimization
functional analysis
how do science
model selection
optimization

Static websites
computers are awful together
diy
doing internet
faster pussycat
plain text
UI
workflow

Single-site web browsers
computers are awful
computers are awful together
confidentiality
UI
Web browser hacks
computers are awful
computers are awful together
faster pussycat
standards
UI

Offline email syncing
communicating
computers are awful
computers are awful together
concurrency hell
confidentiality
distributed
diy
encryption
faster pussycat
office
P2P
plain text
POSIX
Python, compilation and acceleration of
compsci
computers are awful
premature optimization
python

Gradient descent, Newton-like
functional analysis
neural nets
optimization

Indonesian music
music
nusantara
South East Asia

Pornography and other lewd art
gender
photon choreography
sex
wonk

Hugo
academe
faster pussycat
how do science
plain text
workflow


Javascript user interfaces
computers are awful
javascript
UI

Transferring money
computers are awful together
confidentiality
cryptography
money


Life extension, mechanics of
causality
faster pussycat
fit
gene
how do science

Switching to netlify
communicating
computers are awful together
diy
doing internet
faster pussycat
plain text
UI
workflow

Worker- and founder-owned ventures
economics
ethics
incentive mechanisms
institutions
markets
money

Metis and .*-rationality
classification
collective knowledge
culture
ethics
how do science
mind
wonk

Iterated and evolutionary game theory
agents
bounded compute
cooperation
economics
evolution
game theory
incentive mechanisms
mind
Recursive identification
Bayes
dynamical systems
linear algebra
probability
signal processing
state space models
statistics
time series

Economic inequality
cooperation
economics
hand wringing
wonk


Internet for the marginally online
computers are awful
computers are awful together
diy

All we need is hate
cooperation
culture
economics
ethics
evolution
incentive mechanisms
mind
social graph
wonk

Quantified self
causality
economics
faster pussycat
fit
gene
graphical models
how do science
machine learning
mind
probability
statistics

Stochastic Taylor expansion
dynamical systems
Lévy processes
probability
SDEs
signal processing
stochastic processes
time series

Narrative
culture
making things
mind
rhetoric
sociology
wonk
writing

Symbolic regression
compsci
dynamical systems
machine learning
neural nets
optimization
physics
probabilistic algorithms
sciml
statistics
statmech
stochastic processes
stringology


Model interpretation and explanation
adversarial
game theory
hierarchical models
machine learning
sparser than thou
Neural codecs and compression algorithms
compsci
computers are awful
information
metrics
music
photon choreography
standards
Music software
making things
music
signal processing


Fandoms
adaptive
collective knowledge
economics
evolution
game theory
networks
social graph
sociology
writing

Audio sample libraries
data sets
diy
music

Travel checklist
faster pussycat
money
travel

Hallucinations
health
mind
Microsoft Windows for the avoidant
computers are awful
MS Windows

Audio/music corpora
content
data sets
machine listening
music
statistics
time series

Generative music with language+diffusion models
buzzword
computers are awful
generative art
machine learning
making things
music
neural nets

Neural denoising diffusion models
approximation
Bayes
generative
Monte Carlo
neural nets
optimization
probabilistic algorithms
probability
statistics
Voice transcriptions and speech recognition
faster pussycat
language
machine learning
NLP
real time
signal processing
stringology
time series
UI
writing

Effective altruism
cooperation
economics
ethics
game theory
hand wringing

Moral wetware
adaptive
bounded compute
collective knowledge
cooperation
culture
economics
ethics
evolution
extended self
gene
incentive mechanisms
institutions
neuron
utility
wonk

Natural language processing software
grammar
language
machine learning
NLP
stringology


Computational Fluid Dynamics
algebra
functional analysis
linear algebra
PDEs
System identification in continuous time
calculus
dynamical systems
Hilbert space
Lévy processes
machine learning
neural nets
regression
sciml
SDEs
signal processing
sparser than thou
statistics
stochastic processes
time series

Learning graphical models from time series
algebra
graphical models
machine learning
networks
probability
statistics

Neural process regression
functional analysis
Gaussian
generative
Hilbert space
kernel tricks
meta learning
nonparametric
regression
spatial
stochastic processes
time series

Data storage formats
computers are awful
data sets
standards
Learning from ranking, learning to predict ranking
kernel tricks
ordinal
regression
risk

Visualising data
communicating
computers are awful
faster pussycat
generative art
making things
photon choreography

Multi fidelity models
Bayes
machine learning
physics
sciml
statmech
surrogate

Science communication
academe
communicating
faster pussycat
learning
mind
statistics
writing


Machine learning for partial differential equations
calculus
dynamical systems
geometry
Hilbert space
how do science
Lévy processes
machine learning
neural nets
PDEs
physics
regression
sciml
SDEs
signal processing
statistics
statmech
stochastic processes
surrogate
time series
uncertainty
Automatic differentiation
algebra
calculus
computers are awful
functional analysis
linear algebra
number crunching
optimization

Calibration of probabilistic forecasts
model selection
regression
signal processing
statistics
stochastic processes
time series

Feedback system identification, not necessarily linear
calculus
dynamical systems
geometry
how do science
Lévy processes
machine learning
PDEs
physics
regression
sciml
SDEs
signal processing
statistics
statmech
stochastic processes
time series
uncertainty

Generative industrial design
buzzword
computers are awful
generative art
machine learning
making things
music
neural nets
photon choreography

pandoc
academe
computers are awful
faster pussycat
lua
plain text
UI
workflow



Comfort traps
adaptive
incentive mechanisms
learning
mind
utility

Diagrams
communicating
computers are awful
dataviz
faster pussycat
photon choreography

Javascript/browser vector graphics
computers are awful
faster pussycat
photon choreography


Lotekno
making things
music
nusantara
South East Asia
Sunda
Playing video
compsci
computers are awful
information
making things
metrics
music
photon choreography
standards

Big history
adaptive
collective knowledge
economics
evolution
game theory
networks
social graph
sociology
Quantization
Bayes
classification
clustering
compsci
feature construction
information
networks
nonparametric
probability
sparser than thou
statistics

Sexual ethics and institutions
culture
diy
economics
ethics
gender
institutions
life
mind
networks
sex
sociology
squad
wonk

Rationalists in Australia and surrounding regions
crisis
culture
ethics
history
language
mind
wonk

Hydrology, applied
geometry
machine learning
physics
statmech
straya

Non-negative matrix factorisation
feature construction
functional analysis
linear algebra
networks
probability
signal processing
sparser than thou
statistics

Belief propagation with loops
algebra
graphical models
how do science
machine learning
networks
neural nets
probability
statistics
Causal inference under feedback
algebra
graphical models
how do science
machine learning
networks
neural nets
probability
statistics
Learning under distribution shift
algebra
graphical models
how do science
machine learning
networks
probability
statistics

Numerical PDE solvers
algebra
computers are awful
functional analysis
linear algebra
PDEs
premature optimization
sciml

Time management
bounded compute
faster pussycat
incentive mechanisms
mind
Physics-informed neural networks
calculus
dynamical systems
geometry
Hilbert space
how do science
Lévy processes
machine learning
neural nets
PDEs
physics
regression
sciml
SDEs
signal processing
statistics
statmech
stochastic processes
surrogate
time series
uncertainty

Neural PDE operator learning
Especially forward operators. Image-to-image regression, where the images encode a physical process.
calculus
dynamical systems
geometry
Hilbert space
how do science
Lévy processes
machine learning
neural nets
PDEs
physics
regression
sciml
SDEs
signal processing
statistics
statmech
stochastic processes
surrogate
time series
uncertainty
Interpersonal relationships
adaptive
bounded compute
cooperation
culture
ethics
evolution
extended self
gene
institutions
learning
mind
wonk



Wicked tail risks
adaptive
crisis
economics
game theory
how do science
incentive mechanisms
markets
probability
risk
statistics
wonk

Static website editors
computers are awful together
diy
doing internet
faster pussycat
plain text
UI
workflow


Text data processing
computers are awful
data sets
plain text
stringology

Decoupling the economy from energy
ecology
economics
incentive mechanisms
innovation
institutions
intellectual property
physics
snarks
statmech
technology

Material basis of the economy
ecology
economics
physics
snarks
statmech

Brain-like neuronal computation
learning
life
mind
neuron
probability
statistics
statmech


Whom to live amongst
cooperation
culture
economics
housing
incentive mechanisms
institutions
insurgency
making things
policy
spatial
straya
wonk
DNS
computers are awful
computers are awful together
confidentiality

Low-rank matrices
feature construction
functional analysis
high d
linear algebra
networks
probability
signal processing
sparser than thou
statistics

Matrix inverses
feature construction
functional analysis
high d
linear algebra
networks
probability
signal processing
sparser than thou
statistics
Canalization in human learning agents
adaptive
cooperation
evolution
learning
mind
networks
utility

Clickbait bandit problems
bandit problems
culture
economics
mind
reinforcement learning
sociology
UI
utility
wonk
Gradient flows
functional analysis
neural nets
optimization
SDEs
stochastic processes

Misrule, punks and ravers
adaptive
collective knowledge
communicating
cooperation
culture
design
diy
economics
institutions
making things
mind
networks
sociology
squad
status
wonk

Probabilistic numerics
calculus
dynamical systems
geometry
Hilbert space
how do science
Lévy processes
machine learning
neural nets
physics
regression
sciml
SDEs
signal processing
statistics
statmech
stochastic processes
surrogate
time series
uncertainty
Weaponised design
design
making things
the rather superior sort of city
wonk

Machine learning for climate systems
calculus
climate
dynamical systems
geometry
Hilbert space
how do science
machine learning
neural nets
PDEs
physics
regression
sciml
SDEs
signal processing
statistics
statmech
stochastic processes
surrogate
time series
uncertainty
wonk


VS Code / VS Codium
computers are awful
faster pussycat
plain text
UI
workflow

Moloch, slack and hyperselection
cooperation
economics
ethics
utility
wonk

Hybrid machine/human ML
computers are awful
statistics
UI
unsupervised

Ecomodernism
cooperation
economics
hand wringing
life
sustainability
wonk

Coffee and caffeine
food

Data dashboards and ML demos
On assuring the client that you are doing something data-sciency because it looks like in the movies
communicating
computers are awful
data sets
dataviz
faster pussycat
generative art
making things
photon choreography
statistics
UI
workflow

Bayesian inference for misspecified models
Bayes
how do science
statistics
Orthonormal and unitary matrices
algebra
dynamical systems
functional analysis
geometry
high d
linear algebra
measure
signal processing
spheres
stochastic processes
time series

Taking notes
computers are awful
faster pussycat
information provenance
learning
plain text
UI
workflow
Differential geometry, geometric algebra etc
algebra
functional analysis
geometry

Exit/voice dilemmas
adaptive
collective knowledge
economics
evolution
game theory
networks
social graph
sociology

Image file formats
computers are awful
generative art
making things
photon choreography
Unix commands I need often
computers are awful
macos
plain text
POSIX

Cohousing in Australia
cooperation
culture
economics
extended self
housing
incentive mechanisms
institutions
insurgency
making things
policy
spatial
straya
wonk

Emoji
computers are awful
standards
typography
Statistics and machine learning
graphical models
how do science
machine learning
probability
statistics

Footwear
fashion
gear
health
Where next Sydney freaks?
climate
cooperation
culture
economics
housing
incentive mechanisms
institutions
insurgency
making things
policy
spatial
straya
wonk

Akrasia
bounded compute
economics
faster pussycat
incentive mechanisms
mind
utility

Random number generation
computers are awful
Monte Carlo
probabilistic algorithms
probability
pseudorandomness

Incentive alignment problems
economics
extended self
faster pussycat
game theory
incentive mechanisms
institutions
networks
swarm


Informations
classification
compsci
information
metrics
statistics
statmech

Annealing in inference
Bayes
density
Monte Carlo
probabilistic algorithms
probability
statistics
statmech
stochastic processes

Zotero
academe
collective knowledge
computers are awful
faster pussycat
how do science
workflow

Academic writing workflow
academe
faster pussycat
how do science
plain text
workflow


Autism/allism spectrum
communicating
cooperation
culture
mind
sociology
utility

Mirror descent
Bregman
functional analysis
optimization
statmech

Bregman divergences
Bregman
functional analysis
optimization
statmech

Code generation, programming assistants
faster pussycat
language
machine learning
making things
neural nets
NLP
real time
signal processing
stringology
time series
UI
Monte Carlo methods
Bayes
estimator distribution
Monte Carlo
probabilistic algorithms
probability

VS Code as LaTeX editor
computers are awful
faster pussycat
LaTeX
plain text
typography
UI
workflow

Potential theory in probability
algebra
dynamical systems
functional analysis
Lévy processes
PDEs
probability
SDEs
statmech
stochastic processes


Reshipping
money
place
Approximate matrix factorisations and decompositions
feature construction
functional analysis
high d
linear algebra
networks
probability
signal processing
sparser than thou
statistics
Browser machine learning
computers are awful
javascript
machine learning
neural nets
optimization
premature optimization
standards
UI
Remix and copyright
economics
incentive mechanisms
information provenance
institutions
intellectual property
music

Sydney lifestyle theme village
diy
place
policy
straya
wonk

Virtual machines for curmudgeons
computers are awful
diy
macos
MS Windows
POSIX
Making neural models small
bounded compute
edge computing
machine learning
neural nets
sparser than thou

Naming things
computers are awful
cryptography

Generalised autoregressive processes
dynamical systems
Hilbert space
Lévy processes
probability
regression
signal processing
statistics
stochastic processes
time series

Community
cooperation
culture
democracy
economics
institutions
insurgency
rhetoric
social graph
wonk
Secure Scuttlebutt et al
computers are awful together
confidentiality
distributed
diy
economics
P2P

Materials informatics
calculus
dynamical systems
geometry
how do science
machine learning
neural nets
PDEs
physics
regression
sciml
SDEs
statistics
statmech
stochastic processes
stringology
surrogate
time series
uncertainty

Non-uniform signal sampling
dynamical systems
Hilbert space
signal processing
statistics
time series

Doing it yourself
adaptive
collective knowledge
communicating
cooperation
culture
design
diy
economics
institutions
making things
mind
networks
sociology
squad
status
wonk

Doing complicated things the obvious way
adaptive
collective knowledge
cooperation
culture
economics
evolution
faster pussycat
incentive mechanisms
institutions
mind
networks
snarks
sociology
wonk

Modern conspiracy theorising
confidentiality
democracy
economics
evolution
game theory
insurgency
networks
P2P
wonk
Timeless works of art
adaptive
collective knowledge
diy
making things
sociology

Science; Institution design for
academe
agents
collective knowledge
economics
faster pussycat
game theory
how do science
incentive mechanisms
information provenance
institutions
mind
networks
sociology
wonk

DJing
computers are awful
making things
music

Firefox
computers are awful
computers are awful together
faster pussycat
standards
UI

Snowmobile or bicycle?
economics
faster pussycat
innovation
language
machine learning
mind
neural nets
NLP
stringology
technology
UI

Real estate economics
cooperation
culture
economics
housing
incentive mechanisms
institutions
insurgency
making things
policy
spatial
straya
the rather superior sort of city
wonk

Community governance
cooperation
culture
democracy
economics
institutions
insurgency
wonk

Large sample theory
Gaussian
likelihood
optimization
probability
statistics

The social brain
adaptive
adversarial
bounded compute
collective knowledge
cooperation
culture
economics
ethics
evolution
extended self
gene
incentive mechanisms
institutions
mind
networks
neuron
rhetoric
snarks
social graph
sociology
swarm
wonk

Genetic programming
agents
optimization
probabilistic algorithms
swarm

Bitter lessons in compute and cleverness
bounded compute
functional analysis
machine learning
model selection
optimization
statmech
Ablation studies and lesion studies
algebra
graphical models
hidden variables
hierarchical models
how do science
machine learning
mind
networks
probability
sociology
statistics

Learnable coarse-graining
Bayes
machine learning
physics
statmech
surrogate
Plotting in python
communicating
computers are awful
dataviz
photon choreography
python

AV controller interfaces
lua
machine learning
making things
music
real time
UI
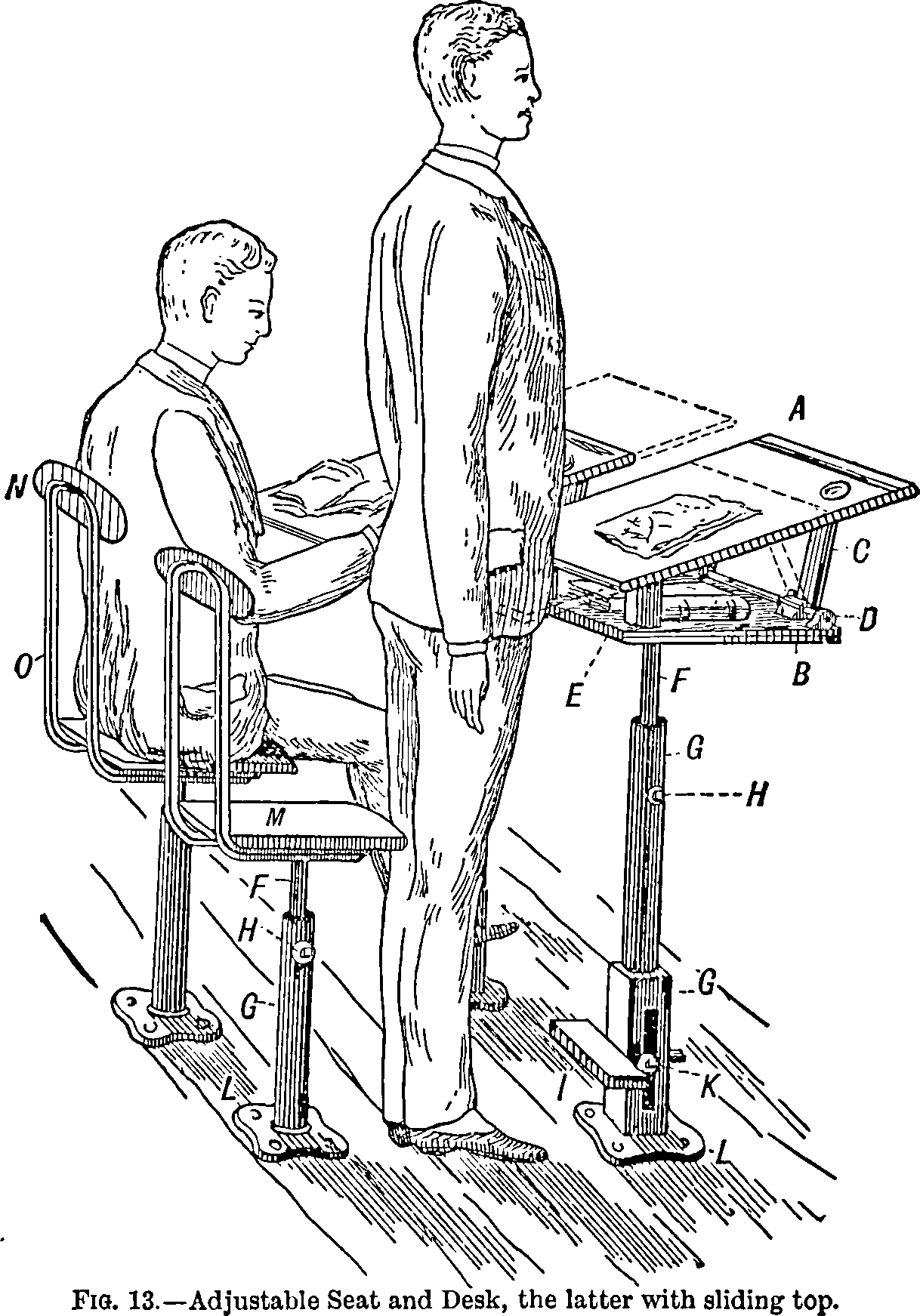
Ergonomics
faster pussycat
health

Noise pollution
cooperation
design
diy
economics
housing
incentive mechanisms
institutions
making things
mind
neuron
policy
spatial
straya
the rather superior sort of city


Polynomial bases
convolution
functional analysis
Hilbert space
nonparametric
signal processing

Gaussian process regression
functional analysis
Gaussian
generative
Hilbert space
kernel tricks
nonparametric
regression
spatial
stochastic processes
time series
Python spatial statistics
data sets
Gaussian
python
spatial
standards
statistics
time series

Semidefinite proramming
functional analysis
optimization
statmech

Model averaging
ensemble
information
model selection
statistics

Matrix calculus
algebra
calculus
functional analysis
linear algebra
optimization

Healthcare in Australia
health
policy
straya
wonk

M-open, M-complete, M-closed
Bayes
how do science
statistics

(Reproducing) kernel tricks
algebra
functional analysis
Hilbert space
kernel tricks
metrics
nonparametric
Devcontainers
computers are awful
diy

The Gaussian distribution
algebra
Gaussian
geometry
high d
linear algebra
measure
probability
signal processing
spheres
statistics
Geoscience
Gaussian
Hilbert space
kernel tricks
spatial
statistics
stochastic processes
time series

Hydra for tracking machine learning experiments
computers are awful
faster pussycat
how do science
information provenance
premature optimization

Bio marker tracking
causality
economics
faster pussycat
fit
gene
institutions
mind

Hypothesis tests, statistical
algebra
Bayes
decision theory
functional analysis
Hilbert space
how do science
linear algebra
machine learning
model selection
nonparametric
statistics
uncertainty

Feed readers
academe
computers are awful together
doing internet
faster pussycat
information provenance
learning
UI
workflow
Reinforcement learning
bandit problems
control
signal processing
stochastic processes
stringology
3d data
computers are awful
faster pussycat
photon choreography
Codebraid
academe
computers are awful
faster pussycat
how do science
information provenance
julia
plain text
premature optimization
python
R
UI
workflow
Calendars and scheduling software
confidentiality
diy
standards

Gaussian process ensembles
algebra
approximation
Gaussian
generative
graphical models
Hilbert space
kernel tricks
machine learning
networks
optimization
probability
statistics

Synchronising config files across machines
computers are awful
computers are awful together
distributed
diy
P2P

Blogdown
academe
doing internet
faster pussycat
how do science
plain text
workflow

The returns on hierarchy in group coordination
cooperation
culture
economics
evolution
extended self
incentive mechanisms
mind
social graph
wonk

Homebrew
compsci
computers are awful
POSIX
premature optimization

Editors for LaTeX
compsci
computers are awful
faster pussycat
LaTeX
typography
UI
Bayes neural nets via subsetting weights
Bayes
convolution
density
likelihood free
machine learning
neural nets
nonparametric
sparser than thou
uncertainty

Rough path theory and signature methods
control
dynamical systems
SDEs
signal processing
sparser than thou
statistics
stochastic processes
time series

Academic reading workflow
academe
computers are awful
faster pussycat
information provenance
learning
UI
workflow

Neural nets with implicit layers
dynamical systems
linear algebra
machine learning
neural nets
optimization
regression
sciml
signal processing
sparser than thou
statmech
stochastic processes
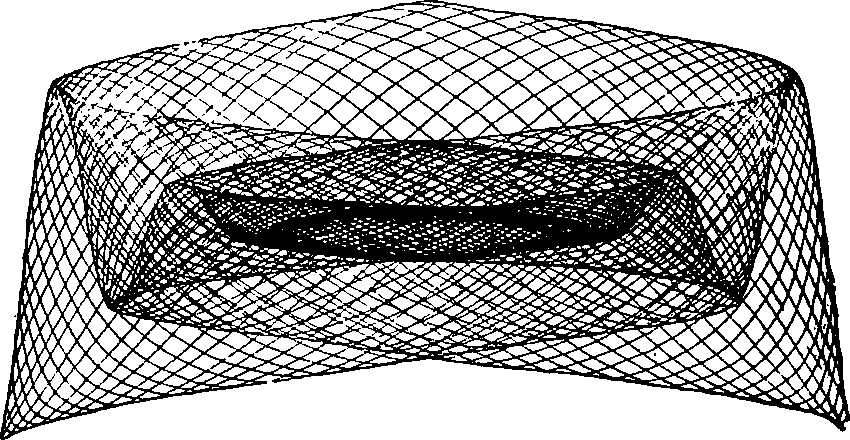
Exponential families
functional analysis
probability
statistics

Position encoding
approximation
dynamical systems
functional analysis
Hilbert space
machine learning
neural nets

Journalism, normative
agents
collective knowledge
cooperation
distributed
economics
game theory
incentive mechanisms
information provenance
institutions
networks
swarm
virality
wonk

Teamwork
communicating
distributed
economics
extended self
faster pussycat
game theory
institutions
learning
mind
networks
squad

Curators of nice bits of internet
computers are awful together
information provenance
making things
Decaying sinusoid dictionaries
dynamical systems
functional analysis
Hilbert space
linear algebra
signal processing
time series

Markdown
academe
computers are awful
faster pussycat
plain text
UI
workflow

Neural nets that do symbolic maths
compsci
language
machine learning
meta learning
networks
neural nets
NLP
stringology

Spatial data in R
computers are awful
data sets
dataviz
faster pussycat
Gaussian
generative art
making things
photon choreography
R
spatial
standards
statistics
Neural vector embeddings
approximation
feature construction
geometry
high d
language
linear algebra
machine learning
metrics
neural nets
NLP
Medicalisation
classification
ethics
health
language
wonk

Noise contrastive estimation
approximation
Bayes
Bregman
feature construction
likelihood free
machine learning
measure
metrics
probability
statistics
time series

Statistical mechanics of statistics
dynamical systems
machine learning
neural nets
physics
sciml
statistics
statmech
stochastic processes

Fish shell
computers are awful
faster pussycat
macos
plain text
POSIX

Bayesian model calibration
functional analysis
how do science
model selection
optimization
statmech
surrogate

Institutions and governance for mass conversation
bandit problems
boring
cooperation
culture
democracy
economics
ethics
mind
rhetoric
snarks
sociology
wonk

Tabular data processing in python
approximation
Bayes
clustering
high d
linear algebra
networks
optimization
probabilistic algorithms
probability
sparser than thou
statistics

Matrix norms, divergences, metrics
algebra
feature construction
functional analysis
high d
Hilbert space
linear algebra
networks
optimization
probability
signal processing
sparser than thou
statistics

PDF, Portable Document Format
computers are awful
information provenance
making things
office
standards

Stylus input
academe
making things
plain text
real time
UI

Livescribe
academe
making things
plain text
real time
UI

Bayes functional regression
functional analysis
Gaussian
generative
Hilbert space
kernel tricks
nonparametric
regression
spatial
stochastic processes
time series

Non-Gaussian Bayesian functional regression
Hilbert space
kernel tricks
PDEs
regression
spatial
stochastic processes
time series

State filtering for hidden Markov models
Bayes
dynamical systems
linear algebra
probability
signal processing
state space models
statistics
time series

Nerdview
language
Singular Value Decomposition
feature construction
functional analysis
high d
linear algebra
networks
probability
signal processing
sparser than thou
statistics
Neural learning dynamical systems
calculus
dynamical systems
geometry
Hilbert space
how do science
Lévy processes
machine learning
neural nets
physics
regression
sciml
SDEs
signal processing
statistics
statmech
stochastic processes
surrogate
time series
uncertainty
Dropbox if you must
computers are awful
computers are awful together
distributed
diy
P2P

Saying “Bayes” is not enough
Bayes
bounded compute
how do science
Monte Carlo
statistics

Gradient descent, first-order, stochastic
functional analysis
neural nets
optimization
SDEs
stochastic processes
Belief propagation and related algorithms
algebra
approximation
Bayes
distributed
dynamical systems
Gaussian
generative
graphical models
machine learning
networks
optimization
probability
signal processing
state space models
statistics
stochastic processes
swarm
time series

Canonical correlation
algebra
Bayes
convolution
functional analysis
Hilbert space
linear algebra
machine learning
model selection
nonparametric
statistics
uncertainty

Method of Adjoints for differentiating through ODEs
Bayes
dynamical systems
linear algebra
probability
signal processing
state space models
statistics
time series

Differentiable PDE solvers
geometry
how do science
machine learning
PDEs
physics
sciml
statmech
stochastic processes
surrogate
uncertainty

Matrix square roots
feature construction
functional analysis
high d
linear algebra
networks
probability
signal processing
sparser than thou
statistics

Jax
algebra
calculus
computers are awful
linear algebra
number crunching
optimization

Databases (for scientists)
computers are awful
concurrency hell
data sets

Conformal prediction
Bayes
statistics
stochastic processes
surrogate
uncertainty

Multi-objective optimisation
economics
machine learning
model selection
neural nets
optimization
regression
sparser than thou
spatial
stochastic processes
time series

Optimal transport inference
functional analysis
measure
metrics
optimization
statistics

Distances between Gaussian distributions
algebra
Gaussian
geometry
high d
linear algebra
measure
probability
signal processing
spheres
statistics

Reparameterization methods for MC gradient estimation
approximation
Bayes
density
likelihood free
Monte Carlo
nonparametric
optimization
probabilistic algorithms
probability
sciml
statistics
Normalizing flows
approximation
Bayes
density
likelihood free
Monte Carlo
nonparametric
optimization
probabilistic algorithms
probability
statistics

Monte Carlo gradient estimation
Bayes
calculus
density
estimator distribution
Monte Carlo
probabilistic algorithms
probability
risk
uncertainty

Combining kernels
Hilbert space
kernel tricks
metrics
signal processing
statistics
stochastic processes

Academic publishing
academe
collective knowledge
diy
doing internet
economics
faster pussycat
how do science
incentive mechanisms
information provenance
institutions
mind
networks
sociology
Numerical libraries
computers are awful
number crunching
premature optimization
python

Scheduling jobs on HPC clusters for modern ML nerds
computers are awful
computers are awful together
concurrency hell
distributed
premature optimization

Probabilistic neural nets
Bayes
convolution
density
likelihood free
machine learning
neural nets
nonparametric
sparser than thou
uncertainty

Neural implicit representations
dynamical systems
functional analysis
machine learning
neural nets
Neural rendering
dynamical systems
functional analysis
machine learning
neural nets
Dynamics of recommender systems and other AI social interventions at societal scale
classification
collective knowledge
confidentiality
culture
economics
ethics
faster pussycat
game theory
how do science
incentive mechanisms
innovation
language
machine learning
mind
neural nets
NLP
sociology
stringology
technology
UI
wonk

Covariance estimation
algebra
functional analysis
Hilbert space
kernel tricks
metrics
nonparametric
regression
sparser than thou
statistics

Generative AI workflows and hacks 2024
economics
faster pussycat
innovation
language
machine learning
neural nets
NLP
stringology
technology
UI
Generative AI workflows and hacks 2023
economics
faster pussycat
innovation
language
machine learning
neural nets
NLP
stringology
technology
UI
Legibility and automation
classification
collective knowledge
confidentiality
culture
ethics
game theory
how do science
incentive mechanisms
sociology
wonk

Lua
computers are awful
lua
number crunching
premature optimization
Model order reduction
feature construction
functional analysis
linear algebra
machine learning
networks
neural nets
PDEs
physics
probability
sparser than thou
statistics
statmech
surrogate
topology

Secure chat systems
communicating
computers are awful
confidentiality
encryption


ΦFlow
geometry
how do science
machine learning
PDEs
physics
statmech
stochastic processes
surrogate
uncertainty

Code editors
compsci
computers are awful
faster pussycat
plain text
UI

How to do research funding
academe
diy
Performance indicators, Measurement, analytics
economics
faster pussycat
incentive mechanisms
institutions
networks
statistics

Online collaboration tools
academe
communicating
computers are awful together
distributed
diy
mind
photon choreography
UI
Indyweb, small web, cozy web
communicating
computers are awful together
diy
doing internet

Leakage in predictive models
estimator distribution
linear algebra
model selection
probability
statistics

Configuring python with “.env” files
computers are awful
python

Cheap talk
bandit problems
cooperation
culture
democracy
economics
ethics
mind
rhetoric
snarks
sociology
wonk
Optimal rotations
algebra
calculus
functional analysis
geometry
high d
linear algebra
measure
optimization
probability
signal processing
sparser than thou
spheres

Mathematica
algebra
compsci
computers are awful
stringology
Webmail systems
communicating
computers are awful
computers are awful together
confidentiality
diy
encryption
faster pussycat
office
plain text
POSIX
UI

Email clients on linux
communicating
computers are awful
computers are awful together
confidentiality
encryption
faster pussycat
office
POSIX
UI

Expectation propagation
approximation
Bayes
concurrency hell
graphical models
probabilistic algorithms
statistics

MLP-Mixer neural networks
machine learning
neural nets
signal processing

Contemporary neo-feudalism & endimming
cooperation
crisis
culture
economics
wonk

Particle filters
Bayes
Monte Carlo
probabilistic algorithms
probability
sciml
signal processing
state space models
statistics
swarm
time series
Practical text generation and writing assistants
faster pussycat
language
machine learning
NLP
real time
signal processing
stringology
UI

Transformer networks
language
machine learning
meta learning
neural nets
NLP
stringology
time series

PDF viewers
computers are awful
information provenance
office
UI
Deep sets
feature construction
functional analysis
linear algebra
machine learning
networks
neural nets
probability
sciml
sparser than thou
statistics
topology

Ensemble Kalman methods
Bayes
distributed
dynamical systems
ensemble
generative
graphical models
linear algebra
machine learning
Monte Carlo
optimization
probabilistic algorithms
probability
sciml
signal processing
state space models
statistics
stochastic processes
swarm
time series

(Nearly-)Convex relation of nonconvex problems
feature construction
functional analysis
Hilbert space
machine learning
optimization
statmech
Markdown editors
academe
computers are awful
faster pussycat
plain text
UI
workflow
Sparse coding with learnable dictionaries
convolution
high d
Hilbert space
linear algebra
nonparametric
optimization
regression
signal processing
sparser than thou
Online whiteboards
academe
communicating
computers are awful together
distributed
diy
mind
photon choreography
UI

Teaching mathematics and especially statistics
academe
communicating
faster pussycat
learning
mind
statistics

Tensor decompositions
algebra
Hilbert space

Transport maps
approximation
Bayes
density
likelihood free
nonparametric
optimization
probabilistic algorithms
probability
statistics

UX
design
making things
photon choreography
UI

Contemporary techno-horror
crisis
culture
history
language
mind
wonk
writing

Disgust
crisis
culture
history
language
mind
wonk

External validity
algebra
graphical models
how do science
machine learning
networks
probability
statistics

Scaling laws for very large neural nets
bounded compute
functional analysis
machine learning
model selection
optimization
statmech
The Matrix-Gaussian distribution
algebra
geometry
high d
linear algebra
measure
probability
signal processing
spheres
statistics
Interoperating with R
computers are awful
number crunching
R
statistics
Jupyter UI wrangling
faster pussycat
premature optimization
python
UIs in Python
computers are awful
concurrency hell
premature optimization
python
UI
Generative flow nets
approximation
Bayes
generative
likelihood free
Monte Carlo
neural nets
optimization
probabilistic algorithms
probability
statistics
unsupervised

Tolerating Jupyter’s file format
faster pussycat
premature optimization
python

Diffusion of innovations
adaptive
collective knowledge
economics
hidden variables
incentive mechanisms
institutions
mind
networks
social graph
sociology
technology
virality
wonk

Shells
computers are awful
faster pussycat

Last-layer Bayes neural nets
algebra
Bayes
convolution
density
functional analysis
Hilbert space
likelihood free
linear algebra
machine learning
nonparametric
sparser than thou
uncertainty

Last-layer Bayes neural nets
Bayes
convolution
density
likelihood free
machine learning
neural nets
nonparametric
sparser than thou
uncertainty

Predictive coding
energy
learning
mind
neuron
probability
statistics
statmech

IDEs for Julia
compsci
computers are awful
julia
UI

manim
communicating
computers are awful
learning
photon choreography
python
Visualising probabilistic graphical models
algebra
computers are awful
dataviz
faster pussycat
graphical models
machine learning
networks
photon choreography
probability
statistics
Maths hacks
faster pussycat
mathematics

Web API automation
browser
compsci
computers are awful together
diy
doing internet
faster pussycat

When to argue ad hominem
adversarial
bandit problems
bounded compute
cooperation
culture
democracy
economics
ethics
mind
rhetoric
snarks
sociology
wonk
Implementing neural nets
computers are awful
machine learning
neural nets
optimization
Conference posters
academe
computers are awful
photon choreography
Web scraping
browser
computers are awful together
confidentiality
diy
doing internet
faster pussycat

Models of inequity
culture
diy
ethics
gender
gene
sex
sociology
wonk
Browser graphics
computers are awful
faster pussycat
photon choreography

Statistics and ML in python
computers are awful
neural nets
python
statistics
Javascript audio
computers are awful
javascript
music
![]()
Research data sharing
academe
data sets
how do science
information provenance

Matplotlib
computers are awful
photon choreography
python



Weaponizing social media
computers are awful together
confidentiality
democracy
economics
evolution
game theory
insurgency
networks
P2P
social graph
virality
wonk


Drugs, recreational
chemistry
health
mind
neuron
Gradients and message-passing
algebra
approximation
Bayes
distributed
dynamical systems
generative
graphical models
machine learning
networks
optimization
probability
signal processing
state space models
statistics
stochastic processes
swarm
time series
Numerical python
compsci
computers are awful
premature optimization
python

Goodhart’s Law
economics
game theory
incentive mechanisms
institutions
machine learning
optimization
statistics
utility

Highly performative computing
computers are awful
computers are awful together
concurrency hell
distributed
premature optimization

Probability divergences
approximation
measure
metrics
optimization
probability
statistics

Password management
computers are awful
computers are awful together
confidentiality
cryptography
security

Image search
computers are awful together
faster pussycat
information provenance
making things
photon choreography
search
standards
Special LaTeX symbols
computers are awful
faster pussycat
LaTeX
typography

Elliptical distributions
algebra
density
geometry
high d
linear algebra
measure
probability
risk
signal processing
spheres
statistics

BibLaTeX
academe
collective knowledge
computers are awful
faster pussycat
how do science
workflow

Transforms of Gaussian noise
approximation
Bayes
dynamical systems
Gaussian
Hilbert space
linear algebra
Lévy processes
Markov processes
networks
optimization
probability
SDEs
signal processing
state space models
statistics
stochastic processes
time series

Bayesian model selection by model evidence maximisation
Bayes
information
model selection
statistics

Meditation and enlightenment
faster pussycat
health
learning
mind
utility

Economic development
cooperation
economics
hand wringing
wonk
Graph neural nets
algebra
functional analysis
geometry
machine learning
networks
neural nets

![]()
Synchronising files across machines
computers are awful
computers are awful together
concurrency hell
distributed
diy
P2P

Open Source (mostly software)
collective knowledge
cooperation
economics
information provenance
innovation
institutions
making things


Machine learning for physical sciences
calculus
dynamical systems
geometry
Hilbert space
how do science
machine learning
neural nets
PDEs
physics
regression
sciml
SDEs
signal processing
statistics
statmech
stochastic processes
surrogate
time series
uncertainty

COVID-19 in practice
branching
count data
diy
fit
health
life
networks
risk
SDEs
stochastic processes
straya
time series
Mind as statistical learner
collective knowledge
learning
life
mind
probability
statistics
statmech
Density ratio tricks
approximation
Bayes
feature construction
likelihood free
machine learning
measure
metrics
probability
statistics
time series

Growing up
cooperation
culture
incentive mechanisms
learning
mind
snarks
wonk
Statistical relational learning
causality
networks
statistics
stringology
Models of computation
compsci
grammar
stringology
Adverse advice selection
algebra
graphical models
how do science
machine learning
networks
probability
statistics

Adverse advice selection
algebra
graphical models
how do science
machine learning
networks
probability
statistics
Conditioning non-specific advice
algebra
collective knowledge
cooperation
culture
economics
ethics
graphical models
how do science
networks
probability
statistics
Hamiltonian and Langevin Monte Carlo
Bayes
generative
geometry
how do science
information
Monte Carlo
physics
statistics

Explorables and interactives
academe
communicating
computers are awful
data sets
dataviz
faster pussycat
generative art
how do science
learning
making things
mind
number crunching
photon choreography
statistics
UI
workflow

But what can I do?
democracy
economics
insurgency
networks
social graph
straya
wonk

Interaction effects and subgroups are probably what we want to estimate
algebra
graphical models
how do science
machine learning
meta learning
networks
probability
statistics
Personalized medicine
causality
economics
faster pussycat
fit
gene
graphical models
how do science
machine learning
mind
probability
statistics

How to communicate
bandit problems
boring
bounded compute
communicating
cooperation
culture
democracy
economics
ethics
extended self
faster pussycat
institutions
mind
rhetoric
snarks
sociology
standards
wonk
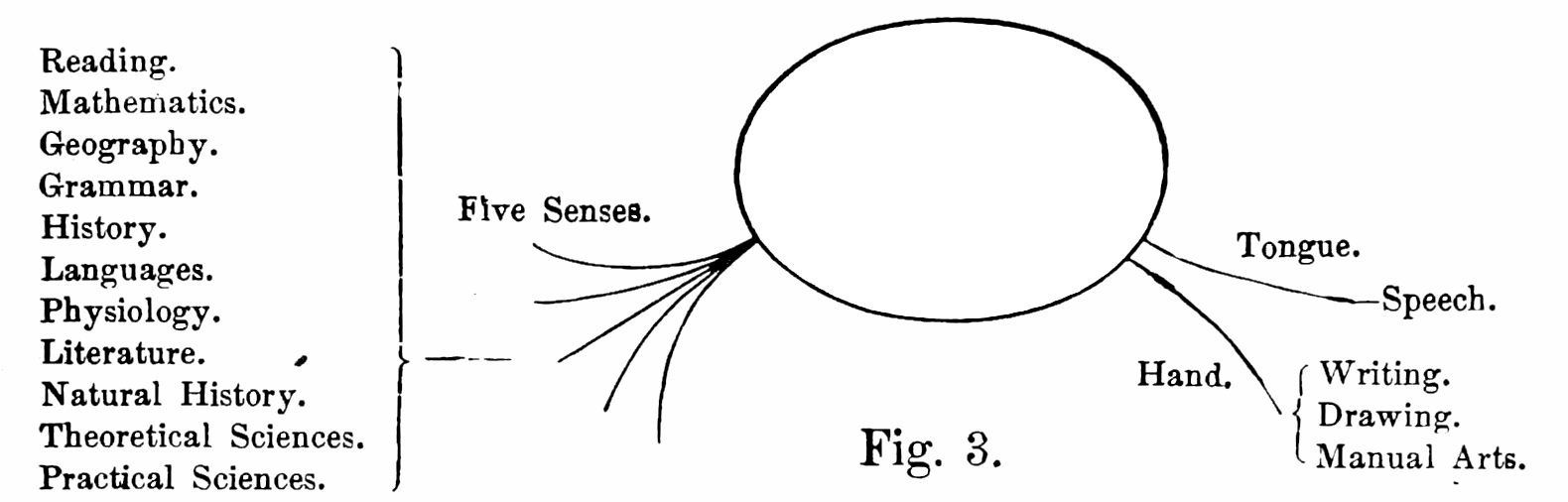
Scientific writing
collective knowledge
communicating
how do science
information provenance
language
making things
writing

Queerness
culture
diy
gender
sex
sociology
wonk

Blogroll
academe
computers are awful together
faster pussycat
information provenance
learning
UI
workflow

Electric cars
diy
hardware
travel

Organising a photo collection
computers are awful
faster pussycat
making things
music
photon choreography
standards

Feelings, applied
adaptive
bounded compute
cooperation
culture
ethics
evolution
gene
incentive mechanisms
institutions
learning
mind
wonk

Email hosts
communicating
computers are awful
computers are awful together
confidentiality
encryption
faster pussycat
How to do research careers
academe
diy

Emancipating my tribe
communicating
cooperation
culture
economics
making things
mind
squad
wonk
Deep learning as a dynamical system
calculus
classification
dynamical systems
geometry
Hilbert space
how do science
Lévy processes
machine learning
neural nets
PDEs
physics
regression
sciml
SDEs
signal processing
statistics
statmech
stochastic processes

The edge of chaos
compsci
dynamical systems
machine learning
neural nets
physics
statistics
statmech
stochastic processes

Pluralism, multiculturalism, politics
bandit problems
boring
cooperation
culture
democracy
economics
ethics
mind
rhetoric
snarks
sociology
wonk
Casual anthropic principles
collective knowledge
cooperation
distributed
game theory
how do science
insurgency
networks
probability
sociology
statistics
wonk
Bayesian sparsity
Bayes
high d
information
model selection
regression
sparser than thou
statistics
Python pickling
computers are awful
concurrency hell
distributed
number crunching
premature optimization
workflow
Python cluster computing
computers are awful
concurrency hell
distributed
number crunching
premature optimization
workflow

Randomised linear algebra
algebra
approximation
feature construction
functional analysis
geometry
high d
linear algebra
measure
metrics
model selection
probabilistic algorithms
probability
signal processing
sparser than thou
Online learning
Bayes
dynamical systems
linear algebra
optimization
probability
signal processing
statistics
time series

Anomaly detection
probability
statistics

Neural tangent kernel
algebra
Bayes
functional analysis
Gaussian
Hilbert space
kernel tricks
machine learning
metrics
model selection
neural nets
nonparametric
optimization
probabilistic algorithms
SDEs
stochastic processes

Editing images
computers are awful
generative art
making things
photon choreography

Continuous and equilibrium probabilistic graphical models
graphical models
machine learning
networks
probability
statistics
Tribal sorting and polarization
collective knowledge
cooperation
distributed
game theory
how do science
insurgency
networks
social graph
sociology
squad
wonk


Forecasting
model selection
regression
signal processing
statistics
stochastic processes
time series

Intellectual property
collective knowledge
cooperation
economics
ethics
incentive mechanisms
innovation
institutions
technology
The blogosphere
academe
faster pussycat
how do science
plain text
workflow
writing
Transcoding
compsci
computers are awful
information
making things
metrics
music
photon choreography
standards
Precision matrix estimation
algebra
functional analysis
Hilbert space
kernel tricks
metrics
nonparametric
regression
sparser than thou
statistics

(Weighted) least squares fits
Hilbert space
linear algebra
optimization
regression
statistics
Biomimetic algorithms
agents
learning
life
neuron
optimization
probabilistic algorithms
swarm
Multi level marketing
collective knowledge
cooperation
distributed
game theory
how do science
insurgency
networks
probability
sociology
statistics
wonk
Learning graphical models from data
algebra
graphical models
machine learning
networks
probability
statistics
Langevin dynamcs MCMC
Bayes
estimator distribution
Markov processes
Monte Carlo
probabilistic algorithms
probability


Bayesian inverse problems in function space
functional analysis
linear algebra
probability
sparser than thou
spatial
statistics

Squads
cooperation
culture
diy
economics
institutions
insurgency
rhetoric
social graph
wonk

Depression
health
mind

Physical infrastructure
cooperation
culture
design
diy
economics
housing
incentive mechanisms
institutions
making things
markets
money
physics
policy
probability
risk
spatial
the rather superior sort of city
wonk

The interpretation of RV densities as point process intensities and vice versa
density
nonparametric
point processes
probability
spatial
statistics
time series

Gaussian process inference by partial updates
functional analysis
Gaussian
generative
geometry
Hilbert space
kernel tricks
optimization
regression
spatial
statistics
stochastic processes
time series

Generalised Ornstein-Uhlenbeck processes
dynamical systems
Hilbert space
Lévy processes
probability
regression
signal processing
statistics
stochastic processes
time series

Conditional expectation and probability
algebra
functional analysis
networks
probability
time series

Posterior Gaussian process samples by updating prior samples
functional analysis
Gaussian
generative
Hilbert space
kernel tricks
regression
spatial
stochastic processes
time series
Ensemble Kalman methods for training neural networks
Bayes
dynamical systems
ensemble
likelihood free
linear algebra
machine learning
Monte Carlo
neural nets
nonparametric
probability
sciml
signal processing
sparser than thou
statistics
statmech
stochastic processes
time series
uncertainty
Penalised/regularised regression
Bayes
functional analysis
linear algebra
model selection
optimization
probability
signal processing
sparser than thou
statistics

Multi-agent self
adaptive
adversarial
bounded compute
collective knowledge
cooperation
culture
economics
ethics
evolution
extended self
gene
incentive mechanisms
institutions
mind
networks
neuron
rhetoric
snarks
social graph
sociology
wonk

LaTeX mathematics hacks
computers are awful
faster pussycat
LaTeX
plain text
typography
UI
workflow
Data versioning
computers are awful
data sets
information provenance
workflow
Laplace approximations in inference
Bayes
feature construction
machine learning
Monte Carlo
probabilistic algorithms
probability
signal processing
state space models
statistics

Soft methodology of science
adaptive
collective knowledge
economics
faster pussycat
how do science
incentive mechanisms
institutions
mind
networks
sociology

Terminals
computers are awful
faster pussycat
plain text
POSIX
Gaussian belief propagation
algebra
approximation
Bayes
distributed
dynamical systems
Gaussian
generative
graphical models
Hilbert space
linear algebra
machine learning
networks
optimization
probability
signal processing
state space models
statistics
stochastic processes
swarm
time series
Scattering transforms
computers are awful
machine learning
machine listening
making things
music
signal processing
sparser than thou

Distributional robustness in inference
adversarial
AI
functional analysis
game theory
learning
metrics
optimization
probability
statistics
State space reconstruction
count data
dynamical systems
stringology
time series


Managing people
adversarial
bounded compute
communicating
cooperation
economics
faster pussycat
game theory
institutions
mind
networks
rhetoric


Factorial hidden Markov models
Bayes
dynamical systems
linear algebra
probability
signal processing
state space models
statistics
time series
Mellin transforms
functional analysis
Hilbert space
linear algebra
signal processing
sparser than thou

Project management
communicating
distributed
economics
faster pussycat
game theory
incentive mechanisms
innovation
institutions
mind
networks
Semantics
classification
communicating
feature construction
high d
language
machine learning
metrics
mind
NLP

Cluster B personality disorders
adversarial
bounded compute
communicating
cooperation
culture
mind
Generic variance reduction in Monte Carlo samplers
Bayes
estimator distribution
Markov processes
Monte Carlo
probabilistic algorithms
probability

Julia interoperation and foreign function interfaces
computers are awful
julia

Elliptical belief propagation
algebra
approximation
Bayes
distributed
dynamical systems
Gaussian
generative
graphical models
Hilbert space
linear algebra
machine learning
networks
optimization
probability
signal processing
state space models
statistics
stochastic processes
swarm
time series


Recommender systems
approximation
Bayes
clustering
high d
linear algebra
networks
optimization
probabilistic algorithms
probability
sparser than thou
statistics

Video editing
computers are awful
making things
music
photon choreography
standards

Practical LaTeX fonts and character sets
computers are awful
faster pussycat
LaTeX
typography

Video conferencing
communicating
computers are awful together
confidentiality
encryption
Automatic differentiation in Julia
algebra
computers are awful
functional analysis
julia
linear algebra
number crunching
optimization

Neural nets with implicit layers
dynamical systems
linear algebra
machine learning
neural nets
optimization
regression
sciml
signal processing
sparser than thou
statmech
stochastic processes

Contemporary rationalists
crisis
culture
ethics
history
language
mind
wonk

Tracking experiments in machine learning
computers are awful
faster pussycat
how do science
information provenance
premature optimization

Observablejs
computers are awful
dataviz
javascript
photon choreography
UI
Vector icons
computers are awful
javascript
UI

Social factors in information security
bounded compute
computers are awful
computers are awful together
confidentiality
cooperation
economics
wonk

Academic blogging workflow
academe
diy
doing internet
faster pussycat
how do science
plain text
workflow

Causal inference on DAGs
algebra
graphical models
how do science
machine learning
networks
probability
statistics

Instumental variables and two stage regression
algebra
graphical models
how do science
machine learning
networks
probability
statistics
Mathematics without LaTeX
compsci
computers are awful
faster pussycat
LaTeX
typography
UI

Learning Gamelan
convolution
functional analysis
music
neural nets
nonparametric
signal processing
sparser than thou

Neural net attention mechanisms
language
machine learning
neural nets
NLP

ELBO
approximation
optimization
probability
statistics

Mechanism design for reputation systems
collective knowledge
cooperation
culture
democracy
economics
ethics
game theory
how do science
mechanism design
mind
networks
rhetoric
social graph
sociology
wonk

Spreadsheetalikes
computers are awful
faster pussycat
number crunching
office
UI

Javascript mathematics
computers are awful
javascript
photon choreography

Virtual private mesh networks
computers are awful together
confidentiality
cryptography
diy

Gaussian process regression software
functional analysis
Gaussian
generative
Hilbert space
kernel tricks
nonparametric
regression
spatial
stochastic processes
time series

Scenius
communicating
distributed
economics
faster pussycat
game theory
institutions
learning
mind
networks

Diversity in teams
agents
collective knowledge
communicating
cooperation
culture
distributed
economics
faster pussycat
game theory
incentive mechanisms
institutions
insurgency
mind
networks
policy
rhetoric
sociology
squad
wonk
Neural learning for spatiotemporal systems
dynamical systems
machine learning
neural nets
sciml
SDEs
signal processing
spatial
stochastic processes
time series
Gamma distributions
Lévy processes
probability
stochastic processes
time series

Bayes linear regression and basis-functions in Gaussian process regression
algebra
approximation
Gaussian
generative
graphical models
Hilbert space
kernel tricks
machine learning
networks
optimization
probability
statistics
Simulating Gaussian processes on a lattice
Gaussian
Hilbert space
kernel tricks
Lévy processes
nonparametric
regression
spatial
stochastic processes
time series

Models of human cultural reproduction
adaptive
collective knowledge
economics
evolution
game theory
networks
social graph
sociology

Subculture dynamics
adaptive
collective knowledge
economics
evolution
game theory
networks
social graph
sociology
![]()
Integrated Nested Laplace Approximation
Bayes
feature construction
machine learning
Monte Carlo
probabilistic algorithms
probability
signal processing
state space models
statistics

Red queen social signal dynamics
adaptive
collective knowledge
economics
ethics
evolution
game theory
networks
social graph
sociology
Bayes for beginners
Bayes
generative
how do science
Monte Carlo
statistics
Partial differential equations
algebra
functional analysis
linear algebra
PDEs

Trauma and resilience
crisis
culture
economics
ethics
health
incentive mechanisms
mind
rhetoric
snarks
sociology
wonk

Data centric AI
computers are awful
data sets
information provenance
workflow
Julia, the programming language
computers are awful
dataviz
julia
number crunching
premature optimization
Fun tricks in non-convex optimisation
functional analysis
optimization
statmech


Empirical mode decomposition
functional analysis
Hilbert space
probability
signal processing
Performance indicators, measurement, analytics
economics
faster pussycat
incentive mechanisms
institutions
networks
statistics

Being stroppy
adaptive
collective knowledge
economics
evolution
game theory
networks
social graph
sociology

Dilemmas of collective action
bounded compute
distributed
economics
game theory
networks
squad
wonk

Rituals and beliefs that bind
agents
collective knowledge
cooperation
culture
democracy
distributed
economics
extended self
game theory
incentive mechanisms
institutions
insurgency
mind
networks
policy
rhetoric
social graph
sociology
squad
wonk

Intro to probability
algebra
graphical models
how do science
machine learning
networks
probability
statistics

Astroturf and artificial reefs
adaptive
collective knowledge
cooperation
culture
design
diy
economics
housing
incentive mechanisms
institutions
making things
policy
sociology
spatial
the rather superior sort of city
wonk

Comfy GNOME shell
computers are awful
diy
POSIX
UI

Hydrology, applied
geometry
machine learning
physics
statmech
straya

Blame engineering
adaptive
cooperation
culture
economics
engineering
ethics
incentive mechanisms
institutions
risk
wonk
Inverse problems
functional analysis
linear algebra
probability
sparser than thou
statistics

Soft incentive mechanism design
bounded compute
economics
faster pussycat
game theory
incentive mechanisms
institutions
networks

Betting
diy
finance
money
probability

Gender identity
culture
diy
extended self
gender
gene
sex
sociology
wonk

Invasive arguments
adaptive
collective knowledge
economics
game theory
hidden variables
incentive mechanisms
institutions
mind
networks
social graph
sociology
virality
wonk

Stochastic signal sampling
dynamical systems
Hilbert space
signal processing
statistics
time series
Signal sampling
dynamical systems
functional analysis
Hilbert space
signal processing
statistics
time series

Rhetoric
adversarial
bounded compute
communicating
cooperation
culture
mind
wonk

Tokenism or table stakes?
communicating
cooperation
culture
economics
mind
wonk

Generic dependency managers
computers are awful
python
Workhacks
communicating
cooperation
economics
faster pussycat
game theory
institutions
mind
money
networks
rhetoric

Political axes, political correlations
collective knowledge
culture
economics
ethics
wonk

Pluralistic ignorance, silent majorities, spiral of silence, hidden tribes
causality
collective knowledge
cooperation
distributed
insurgency
mind
networks

Institutions
cooperation
economics
hand wringing
incentive mechanisms
institutions
snarks
wonk


Attention management tips for web browsing
bounded compute
computers are awful
computers are awful together
faster pussycat
incentive mechanisms
mind
standards
UI

Markov Chain Monte Carlo methods
Bayes
estimator distribution
generative
Markov processes
Monte Carlo
probabilistic algorithms
probability

Markov decision problems
bandit problems
control
dynamical systems
linear algebra
optimization
probability
signal processing
statistics
stochastic processes
stringology
time series
Plants
gender
gene
life
photon choreography
self similar
sex
star omics
wonk
The Illawarra
diy
place
policy
straya
wonk

Overparameterization in large models
decision theory
feature construction
machine learning
model selection
neural nets
optimization
probabilistic algorithms
SDEs
statmech
stochastic processes

Machine learning and statistics in Julia
computers are awful
julia
neural nets
number crunching
optimization
premature optimization
python
statistics

Emergent spacetime
functional analysis
geometry
networks
physics
probability
quantum
statistics
statmech
Podcasts
content
music

Stochastic partial differential equations
dynamical systems
Lévy processes
probability
SDEs
signal processing
spatial
stochastic processes
time series
Applied psephology
Bayes
hidden variables
hierarchical models
insurgency
networks
regression
statistics
wonk

Funerals and other end-of-life stuff
diy
economics
fashion
sustainability
GUIs for numerical array data
computers are awful
data sets
number crunching
spatial
statistics
UI

Database and data file GUIs
computers are awful
data sets
statistics
UI
Crowd-sourced science
buzzword
collective knowledge
distributed
economics
game theory
how do science
information provenance
spatial
the rather superior sort of city
Nested sampling
Bayes
Monte Carlo
probabilistic algorithms
probability
signal processing
state space models
statistics
swarm
time series

Memetics
adaptive
collective knowledge
economics
hidden variables
incentive mechanisms
institutions
learning
mind
networks
social graph
sociology
virality
wonk
communicating
computers are awful
computers are awful together
confidentiality
encryption
faster pussycat
office

System identification using particle filters
Bayes
Monte Carlo
probabilistic algorithms
probability
sciml
signal processing
state space models
statistics
time series
(Discrete-measure)-valued stochastic processes
classification
machine learning
nonparametric
probability
regression
SDEs
spatial
statistics
stochastic processes
uncertainty

Forecasting with model averaging
dynamical systems
ensemble
model selection
regression
signal processing
statistics
stochastic processes
time series

Measure-valued stochastic processes
functional analysis
kernel tricks
machine learning
nonparametric
PDEs
physics
point processes
probability
regression
SDEs
spatial
statistics
stochastic processes
uncertainty

Linux audio
computers are awful
diy
making things
music
knitr/RMarkdown etc
faster pussycat
how do science
premature optimization
R
workflow

Farming and husbandry of black swans and dragon kings
crisis
density
economics
how do science
incentive mechanisms
markets
probability
risk
statistics
Causal graphical model reading group 2022
algebra
how do science
machine learning
networks
probability
statistics

Inference without KL divergence
approximation
Bayes
how do science
measure
metrics
Monte Carlo
probability
statistics

Generalized Bayesian Computation
approximation
Bayes
functional analysis
generative
how do science
measure
metrics
Monte Carlo
nonparametric
probability
statistics
stochastic processes
SLAM
algebra
approximation
Bayes
distributed
dynamical systems
Gaussian
generative
graphical models
Hilbert space
linear algebra
machine learning
networks
optimization
probability
signal processing
state space models
statistics
stochastic processes
swarm
time series

Vecchia factoring of GP likelihoods
algebra
approximation
Gaussian
generative
graphical models
Hilbert space
kernel tricks
machine learning
networks
optimization
probability
statistics

Synchrony between things, especially organisms
dynamical systems
making things
music
signal processing
sync

Utopian governance
economics
extended self
incentive mechanisms
institutions
markets
money
wonk

Groupthink and the wisdom of crowds
cooperation
culture
democracy
distributed
economics
extended self
rhetoric
sociology
squad
wonk

Voting systems
cooperation
economics
game theory
incentive mechanisms
institutions
ordinal
wonk
Hierarchical models
DAGs, multilevel models, random coefficient models, mixed effect models, structural equation models…
hidden variables
hierarchical models
machine learning
meta learning
networks
probability
regression
statistics

Model fairness
adversarial
game theory
machine learning
wonk

Social media if you must
computers are awful
computers are awful together
confidentiality
diy
doing internet
fit
mind
wonk

Markov bridge processes
Lévy processes
point processes
probability
spatial
stochastic processes

Divisible, decomposable and stable distributions
dynamical systems
linear algebra
Lévy processes
probability
SDEs
stochastic processes
time series

Email clients
communicating
computers are awful
computers are awful together
confidentiality
encryption
faster pussycat
office
UI

Tracking my website traffic
computers are awful together
faster pussycat
UI
workflow

Social norms
culture
economics
ethics
institutions
mind
networks
social graph
standards
virality


This is a simulation
complexity
compsci
economics
how do science
innovation
mind
pseudorandomness
quantum
statmech
technology

Beta Processes
algebra
geometry
linear algebra
Lévy processes
measure
probability
signal processing
sparser than thou
stochastic processes
time series
Stationary Gamma processes
algebra
geometry
linear algebra
Lévy processes
measure
probability
signal processing
sparser than thou
stochastic processes
time series
Particle Markov Chain Monte Carlo
algebra
approximation
Bayes
distributed
dynamical systems
generative
graphical models
machine learning
Monte Carlo
networks
optimization
probabilistic algorithms
probability
signal processing
state space models
statistics
stochastic processes
swarm
time series
Typesetting algorithms in LaTeX
compsci
computers are awful
faster pussycat
LaTeX
plain text
typography
UI
workflow

Bayesian nonparametric statistics
Bayes
functional analysis
Gaussian
generative
how do science
Monte Carlo
nonparametric
statistics
stochastic processes

The levels of simulacra
adaptive
collective knowledge
economics
ethics
evolution
game theory
language
networks
semantics
sociology

Myths
culture
making things
mind
rhetoric
sociology
wonk

Probabilistic neural nets
Bayes
convolution
density
likelihood free
machine learning
neural nets
nonparametric
sparser than thou
uncertainty
Plotting for the web
computers are awful
dataviz
faster pussycat
photon choreography
UI

Playing music on the computer
computers are awful
faster pussycat
making things
music
photon choreography
standards
Beta and Dirichlet distributions
classification
Lévy processes
probability
stochastic processes
time series

Attention economy
bandit problems
bounded compute
culture
democracy
economics
mind
rhetoric
sociology
wonk

Gumbel (soft) max tricks
classification
metrics
probability
statistics

Change points
Bayes
metrics
Monte Carlo
probabilistic algorithms
signal processing
state space models
statistics
stochastic processes
time series

Pólya-Gamma augmentation trick
classification
probabilistic algorithms
probability
statistics
The language game
adaptive
agents
classification
collective knowledge
communicating
economics
evolution
information
language
learning
mind
networks
social graph
sociology
standards
stringology
virality

Detecting stationarity in stochastic processes
Hilbert space
kernel tricks
metrics
signal processing
statistics
stochastic processes

Partition-valued random variates
algebra
graphical models
machine learning
networks
PDEs
physics
point processes
probability
spatial
statistics
stochastic processes
uncertainty
Digital scientific workbooks
academe
computers are awful
faster pussycat
how do science
information provenance
plain text
premature optimization
UI
workflow
Random binary vectors
classification
compsci
information
metrics
statistics

Measure-valued random variates
functional analysis
kernel tricks
machine learning
nonparametric
PDEs
physics
point processes
probability
regression
SDEs
spatial
statistics
stochastic processes
uncertainty

Cloud ML compute vendors
computers are awful
concurrency hell
distributed
number crunching
premature optimization
workflow

Reservoir Computing
dynamical systems
feature construction
machine learning
networks
neural nets
probabilistic algorithms
statmech
stochastic processes

Simulating Gaussian processes
Gaussian
Hilbert space
kernel tricks
Lévy processes
nonparametric
regression
spatial
stochastic processes
time series
Life-adjusted quality years
diy
fit
health
life
risk
social graph
straya
Multivariate Gamma distributions
algebra
geometry
high d
Lévy processes
measure
probability
signal processing
sparser than thou
spheres
stochastic processes

Wiener-Khintchine representations
functional analysis
Hilbert space
optimization
signal processing
stochastic processes
Configuring machine learning experiments
computers are awful
faster pussycat
how do science
information provenance
premature optimization

Sparse coding
convolution
high d
Hilbert space
linear algebra
nonparametric
optimization
regression
signal processing
sparser than thou
Survival analysis and reliability
density
nonparametric
point processes
probability
statistics
time series
Website cheat codes
computers are awful
making things
photon choreography
UI

Plotting in R
computers are awful
photon choreography
R
statistics
Self-supervised learning
hidden variables
likelihood free
nonparametric
statistics
unsupervised

Race, politics of
communicating
culture
economics
ethics
gene
mind
rhetoric
snarks
sociology
wonk

Opinion dynamics 1: Social contagion moves hearts and minds
adaptive
collective knowledge
cooperation
culture
economics
hidden variables
how do science
institutions
learning
mind
networks
snarks
sociology
swarm
virality
wonk
Fun with rotational symmetries
algebra
functional analysis
geometry
high d
linear algebra
measure
probability
signal processing
sparser than thou
spheres

Matrix- and vector-valued generalizations of Gamma processes
linear algebra
Lévy processes
probability
stochastic processes
Lévy Gamma processes
Lévy processes
probability
stochastic processes
time series

Gaussian processes on lattices
Bayes
dynamical systems
linear algebra
probability
signal processing
state space models
statistics
time series

OODA loops
agents
collective knowledge
cooperation
culture
democracy
distributed
dynamical systems
economics
game theory
incentive mechanisms
institutions
insurgency
optimization
time series
wonk

Institutions for devils
agents
collective knowledge
cooperation
culture
democracy
distributed
economics
game theory
incentive mechanisms
institutions
insurgency
mind
networks
policy
rhetoric
social graph
sociology
wonk

Learning Gaussian processes which map functions to functions
Gaussian
generative
geometry
Hilbert space
how do science
kernel tricks
machine learning
PDEs
physics
regression
spatial
stochastic processes
time series

Learning with conservation laws, invariances and symmetries
algebra
how do science
information
machine learning
networks
physics
probability
sciml
statistics
statmech
Subordinators
branching
point processes
probability
stochastic processes

Stability in dynamical systems
dynamical systems
functional analysis
probability
statistics

DIY VPN access point
computers are awful together
confidentiality
cryptography
diy


Audio sample management
computers are awful
content
data sets
diy
machine listening
making things
music
search
signal processing
Moral calculus
ethics
machine learning
wonk
M-estimation
likelihood
optimization
statistics

Our eating disorder
food
health
mind
Politics as statistical learner
collective knowledge
ethics
institutions
learning
life
mind
probability
statistics
statmech

Reproducible research
academe
collective knowledge
how do science
information provenance
workflow

Betting and prediction markets
crisis
economics
how do science
incentive mechanisms
markets
probability
risk
Neurons
compsci
life
machine learning
mind
networks
neuron

Ergodicity and mixing
dynamical systems
Markov processes
statmech
time series

Window management in macOS
computers are awful
diy
macos
POSIX
UI


Diversity in society
agents
collective knowledge
communicating
cooperation
culture
democracy
distributed
economics
faster pussycat
game theory
incentive mechanisms
institutions
insurgency
mind
networks
policy
rhetoric
sociology
wonk
Visual node based programming
compsci
computers are awful
making things
signal processing

Probabilistic programming
Bayes
generative
how do science
Monte Carlo
statistics

Experimental ethics and observational data
communicating
mind
probability
statistics

Variational inference
approximation
metrics
optimization
probabilistic algorithms
probability
statistics

Probabilistic graphical models
algebra
graphical models
machine learning
networks
probability
statistics

Random graphical models
algebra
graphical models
machine learning
networks
probability
statistics
Evolution
adaptive
evolution
gene
incentive mechanisms
optimization

Cryptocurrencies
computers are awful together
confidentiality
cryptography
money

Phylogeny
how do science
life
self similar
star omics
topology


Outsourcing, applied
economics
faster pussycat
making things
money
Visualising geospatial data
communicating
computers are awful
dataviz
faster pussycat
generative art
making things
photon choreography
spatial

Sociology and politics of information
adaptive
collective knowledge
distributed
economics
hidden variables
incentive mechanisms
institutions
mind
networks
social graph
sociology
virality
wonk

Neural nets with basis decomposition layers
convolution
dynamical systems
Hilbert space
linear algebra
machine learning
neural nets
nonparametric
optimization
regression
signal processing
sparser than thou
statmech
stochastic processes

Here’s how I would do art with machine learning if I had to
buzzword
computers are awful
generative art
machine learning
making things
music
neural nets
photon choreography
Karhunen-Loève expansions
convolution
functional analysis
Gaussian
Hilbert space
kernel tricks
metrics
nonparametric
signal processing
statistics
stochastic processes
Indonesia
nusantara
place

Running neural nets backwards
dynamical systems
linear algebra
machine learning
neural nets
optimization
regression
signal processing
sparser than thou
statmech
stochastic processes
Spatial processes and statistics thereof
data sets
Gaussian
Hilbert space
spatial
standards
statistics
Bootstrap
estimator distribution
nonparametric
probabilistic algorithms
statistics
uncertainty
Learning on manifolds
functional analysis
Gaussian
geometry
Hilbert space
how do science
kernel tricks
machine learning
networks
PDEs
physics
regression
signal processing
spatial
statistics
stochastic processes
time series
uncertainty
Prepping for the end of (my access to) the (industrialised) world
cooperation
crisis
economics
fashion
hand wringing
social graph
wonk
Quantum computing
compsci
physics
quantum
statmech

Feedback system identification, linear
calculus
dynamical systems
geometry
Hilbert space
how do science
Lévy processes
machine learning
neural nets
PDEs
physics
regression
sciml
SDEs
signal processing
statistics
statmech
stochastic processes
surrogate
time series
uncertainty
(Outlier) robust statistics
functional analysis
likelihood
optimization
statistics

E-readers
academe
computers are awful
faster pussycat
information provenance
learning
UI
workflow

Dunning-Kruger theory of society
cooperation
culture
how do science
incentive mechanisms
mind
snarks
wonk
Dunning-Kruger theory of institutions
cooperation
culture
evolution
how do science
incentive mechanisms
institutions
mind
snarks
wonk
Android hacks
computers are awful
portable

Care and feeding of macOS filesystems
computers are awful
macos
standards


Software package managers
computers are awful
premature optimization

Risk perception and communication
communicating
crisis
mind
probability
risk
statistics
wonk

Faust, the DSP language
making things
music
signal processing

Bounded rationality
bounded compute
economics
mind
sociology
Social psychology
cooperation
culture
economics
ethics
how do science
mind
networks
rhetoric
snarks
social graph
sociology
wonk
Bayesian inverse problems
functional analysis
linear algebra
probability
sparser than thou
statistics

Gamma-Beta algebra
classification
Lévy processes
probability
stochastic processes
time series
Categorical random variates
classification
metrics
probability
regression
statistics
Linux-compatible laptops
compsci
computers are awful
hardware
POSIX
premature optimization

Hardened desktop operating systems
computers are awful
confidentiality
wonk
Statistical projectivity
distributed
networks
probability
statistics

Standards hell
culture
economics
game theory
institutions
networks
standards
Mind as statistical learner
collective knowledge
life
mind
probability
statistics
statmech

Presentations
academe
communicating
faster pussycat
office
photon choreography
standards
Calendars and contacts GUIs for Linux
computers are awful
computers are awful together
diy
faster pussycat
office
POSIX
standards
UI

R packaging, installation etc
computers are awful
R
statistics
Matrix-valued random variates
algebra
geometry
high d
linear algebra
measure
probability
signal processing
spheres
statistics
stochastic processes


Music software frameworks
computers are awful
lua
making things
music
signal processing


Group size
cooperation
culture
democracy
economics
ethics
extended self
mind
networks
rhetoric
snarks
social graph
sociology
squad
wonk

Time frequency analysis
functional analysis
Hilbert space
probability
signal processing

Garbled highlights from NeurIPS 2021
neural nets
statistics

R
computers are awful
number crunching
R
statistics

Diversity as an end in itself
agents
collective knowledge
communicating
cooperation
culture
democracy
economics
ethics
faster pussycat
game theory
incentive mechanisms
institutions
insurgency
mind
networks
policy
rhetoric
sociology
wonk

Causality via potential outcomes
algebra
graphical models
how do science
machine learning
networks
probability
statistics

Gradient descent, Newton-like, stochastic
functional analysis
neural nets
optimization
SDEs
stochastic processes
Variational state filtering
Bayes
dynamical systems
linear algebra
optimization
probability
signal processing
state space models
statistics
time series


Convolutional subordinator processes
functional analysis
kernel tricks
machine learning
PDEs
physics
point processes
regression
spatial
statistics
stochastic processes
time series
uncertainty

Random rotations
algebra
functional analysis
geometry
high d
linear algebra
measure
probability
signal processing
sparser than thou
spheres

Multi-output Gaussian process regression
Gaussian
Hilbert space
kernel tricks
regression
spatial
stochastic processes
time series

Pyro
Bayes
generative
how do science
Monte Carlo
sciml
statistics


Gaussian Processes as stochastic differential equations
algebra
approximation
Bayes
distributed
dynamical systems
Gaussian
generative
graphical models
Hilbert space
kernel tricks
linear algebra
machine learning
networks
optimization
probability
sciml
signal processing
state space models
statistics
stochastic processes
time series


t-processes, t-distributions
Gaussian
Hilbert space
kernel tricks
Lévy processes
nonparametric
regression
spatial
stochastic processes
time series
Genre speciation
classification
music
semantics

Windows Subsystem for Linux
computers are awful
MS Windows
POSIX

Convolutional neural networks
machine learning
neural nets
signal processing

Trading, hedging and portfolios in practice
diy
finance
money
probability
Gamification
bandit problems
mind
reinforcement learning
UI
wonk
Lévy processes
branching
Lévy processes
point processes
probability
spatial
statmech
stochastic processes

Financing utopia
economics
incentive mechanisms
institutions
markets
money
Cooperation amongst humans
cooperation
culture
economics
evolution
extended self
social graph
wonk

Deep generative models
approximation
Bayes
generative
likelihood free
Monte Carlo
neural nets
optimization
probabilistic algorithms
probability
statistics
unsupervised

Digital nostalgia
computers are awful
information provenance
making things

Tip me
computers are awful
cryptography
money

Editing images with machine learning
computers are awful
generative art
making things
photon choreography
Sexy plants
gender
gene
life
photon choreography
self similar
sex
star omics
wonk

High dimensional statistics
functional analysis
high d
linear algebra
probability
signal processing
sparser than thou

Teaching and doing mathematics remotely
academe
communicating
mind
photon choreography
UI


Probably Approximately Correct
machine learning
optimization
statistics

Trousers
diy
economics
fashion
sustainability
wonk

Survey modelling
Bayes
confidentiality
hidden variables
hierarchical models
mind
networks
ordinal
regression
sociology
statistics
wonk

First aid
diy
health
how do science
Eyewear
fashion
gear
health

Networks and graphs, theory thereof
clustering
dynamical systems
networks
topology
Knowledge geometry
collective knowledge
how do science
stringology
topology
Economics on networks
culture
economics
game theory
institutions
mind
networks
standards
Neural music synthesis
algebra
generative art
machine learning
machine listening
making things
music
networks
probability
signal processing
statistics
(Geo)spatial data sets
computers are awful
data sets
spatial
statistics

Fun with determinants
algebra
functional analysis
Gaussian
Hilbert space
linear algebra

Random neural networks
dynamical systems
feature construction
machine learning
networks
neural nets
probabilistic algorithms
statmech
stochastic processes

Dual booting MS Windows and linux
compsci
computers are awful
MS Windows
POSIX
premature optimization

Planning under uncertainty
Bayes
collective knowledge
economics
how do science
mind
sociology

Multilinear algebra
algebra
functional analysis
Hilbert space
linear algebra

Missing data
hidden variables
hierarchical models
machine learning
networks
probability
regression
statistics

Gradient descent at scale
functional analysis
machine learning
model selection
optimization
premature optimization
statmech
Regularising neural networks
machine learning
model selection
neural nets
sparser than thou
Science for policy
communicating
crisis
economics
ethics
how do science
mind
probability
risk
statistics
wonk
Fractals and self-similarity
model selection
photon choreography
regression
self similar
signal processing
statistics
stochastic processes
time series
Economics of automation
economics
faster pussycat
innovation
language
machine learning
mind
neural nets
technology
UI
Arpeggiate by numbers
algebra
generative art
making things
music
stringology

Approximate Bayesian Computation
Bayes
feature construction
likelihood free
machine learning
Monte Carlo
probabilistic algorithms
probability
signal processing
state space models
statistics
time series

Fonts
making things
typography

Heavy tails
density
point processes
probability
risk
statistics
GIFs
computers are awful
photon choreography
premature optimization
standards
Software engineering for scientists
academe
collective knowledge
computers are awful
how do science
information provenance
workflow
Meta learning
functional analysis
how do science
meta learning
model selection
optimization
statmech
Natural language processing
grammar
language
machine learning
NLP
stringology

Biological basis of language
grammar
language
machine learning
NLP
stringology

Fractional differential equations
branching
calculus
functional analysis
Hilbert space
self similar
statistics

User interface design
computers are awful
photon choreography
UI

Maths hacks
faster pussycat
mathematics
Software video routers
making things
music
signal processing
Wirtinger calculus
functional analysis
Hilbert space
optimization

Recurrent neural networks
machine learning
networks
neural nets
signal processing
time series

Governance of the commons
cooperation
culture
distributed
economics
hand wringing
incentive mechanisms
mind
networks
policy
sociology
wonk

Path smoothness properties of stochastic processes
functional analysis
probability
stochastic processes
time series
Cloud machine learning
computers are awful
concurrency hell
distributed
number crunching
premature optimization
workflow

Stochastic calculus
dynamical systems
Lévy processes
probability
SDEs
signal processing
stochastic processes
time series
VS Code as R IDE
computers are awful
number crunching
plain text
R
statistics
UI
workflow

Baby’s first private cloud
computers are awful together
confidentiality
cryptography
wonk
Home networks for lazy dummies
computers are awful together
confidentiality
cryptography
diy


Vector Gaussian processses
Gaussian
Hilbert space
kernel tricks
regression
spatial
stochastic processes
time series

Convolutional stochastic processes
Gaussian
geometry
Hilbert space
how do science
kernel tricks
machine learning
PDEs
physics
regression
signal processing
spatial
statistics
stochastic processes
time series
uncertainty

Essays in stochastic processes
count data
regression
sparser than thou
time series

Virtual private networks
computers are awful together
confidentiality
cryptography
diy

Why is Australian internet shit?
computers are awful together
data sets
straya
Design grammars
generative art
grammar
making things
photon choreography
self similar
stringology

Grammar induction
generative art
grammar
language
machine learning
stringology

Risk neutral measure
diy
finance
money
probability
Hardened mobile
computers are awful
confidentiality
edge computing
encryption

Generalized linear models
machine learning
optimization
regression
statistics

GPU computation
computers are awful
concurrency hell
number crunching
premature optimization

Sequential experiments
functional analysis
how do science
model selection
optimization
statmech
surrogate

Cascade models
branching
count data
probability
time series
Models for count data
branching
count data
regression
statistics

Unix/linux distros explained as bikes
computers are awful
diy
POSIX
snarks

Neural network activation functions
machine learning
neural nets
Games, computer, recreational
computers are awful
lua
mind
Contact tracing
branching
computers are awful
computers are awful together
confidentiality
count data
health
life
networks
stochastic processes
time series
wonk

Generic cloud machines
computers are awful
concurrency hell
number crunching
premature optimization
workflow
Publication bias
collective knowledge
how do science
information provenance
statistics

Science
academe
agents
collective knowledge
economics
faster pussycat
game theory
how do science
incentive mechanisms
information provenance
institutions
mind
networks
sociology
wonk
IDEs for R
computers are awful
number crunching
R
statistics

Contagion processes and their statistics
branching
count data
networks
probability
SDEs
statistics
stochastic processes
time series
virality

Media virality
branching
computers are awful together
confidentiality
count data
democracy
economics
evolution
game theory
insurgency
networks
P2P
probability
SDEs
social graph
statistics
stochastic processes
time series
virality
wonk
Learning summary statistics
feature construction
functional analysis
linear algebra
machine learning
networks
neural nets
probability
sciml
sparser than thou
statistics
topology
GPU computation out of the cloud
computers are awful
concurrency hell
premature optimization

Multi-task ML
edge computing
machine learning
neural nets
regression
sparser than thou
spatial
stochastic processes
time series

How to reduce corporate spying
computers are awful
computers are awful together
confidentiality
wonk
Tensorflow
computers are awful
neural nets
optimization
premature optimization
python
statistics
Point process intensities and statistical estimation thereof
branching
point processes
spatial
statmech

Monetizing my music
economics
intellectual property
making things
money
music


Uncertainty quantification
Bayes
statistics
stochastic processes
surrogate
uncertainty

Semi/weakly-supervised learning
density
hidden variables
statistics
unsupervised
Moral philosophy
collective knowledge
culture
economics
ethics
machine learning
wonk
Extreme value theory
density
point processes
probability
risk
statistics
Distributed sensing, swarm sensing, adaptive social learning
agents
bounded compute
collective knowledge
concurrency hell
distributed
economics
edge computing
extended self
game theory
incentive mechanisms
machine learning
networks
swarm


Marine biology and ecology
adaptive
ecology
gene
life

Gaussian processes
Gaussian
Hilbert space
kernel tricks
Lévy processes
nonparametric
regression
spatial
stochastic processes
time series

Backward stochastic differential equations
dynamical systems
Lévy processes
probability
SDEs
signal processing
stochastic processes
time series
Stochastic differential equations
dynamical systems
Lévy processes
probability
sciml
SDEs
signal processing
stochastic processes
time series
Learning on tabular data
approximation
Bayes
clustering
high d
linear algebra
networks
optimization
probabilistic algorithms
probability
sparser than thou
statistics
Random-forest-like methods
classification
ensemble
model selection
nonparametric
optimization
regression
Voice fakes
dynamical systems
language
machine learning
NLP
optimization
signal processing
time series
Organising a music collection
computers are awful
faster pussycat
making things
music
search
signal processing
standards

Optimal transport metrics
approximation
functional analysis
measure
metrics
optimization
probability
statistics

Energy based models
approximation
Bayes
generative
Monte Carlo
optimization
probabilistic algorithms
probability
statistics
statmech

Ecology
adaptive
ecology
gene
life

What is your Sydney housing endgame?
cooperation
culture
economics
housing
incentive mechanisms
institutions
insurgency
making things
policy
spatial
straya
wonk

Isotropic random vectors
algebra
functional analysis
geometry
high d
linear algebra
measure
probability
signal processing
sparser than thou
spheres

Neural net kernels
Hilbert space
kernel tricks
machine learning
metrics
probabilistic algorithms
signal processing
spheres
statistics
stochastic processes

Randomized low dimensional projections
algebra
approximation
feature construction
functional analysis
geometry
high d
linear algebra
measure
metrics
probability
signal processing
sparser than thou
spheres
Burning bootable USB drives, SD cards etc
computers are awful
diy
Transforms of random variates
Hilbert space
Lévy processes
Markov processes
probability
SDEs
stochastic processes
Cross validation
estimator distribution
linear algebra
model selection
probability
statistics

Complexity of markets
economics
incentive mechanisms
institutions
markets
money
Deep Gaussian process regression
Gaussian
generative
Hilbert space
kernel tricks
regression
spatial
stochastic processes
time series

Infinite width limits of neural networks
algebra
Bayes
feature construction
functional analysis
Gaussian
Hilbert space
kernel tricks
machine learning
metrics
model selection
neural nets
nonparametric
probabilistic algorithms
SDEs
stochastic processes
Computational symbolic mathematics
algebra
compsci
computers are awful
stringology

Compressing neural nets
edge computing
machine learning
model selection
neural nets
sparser than thou

Spectral factorization
dynamical systems
linear algebra
probability
signal processing
state space models
statistics
stochastic processes
time series
Wiener-Hopf method
dynamical systems
linear algebra
probability
signal processing
state space models
statistics
stochastic processes
time series

Fourier transforms
functional analysis
Hilbert space
linear algebra
signal processing
sparser than thou
![]()
Free will
boring
how do science
mind
snarks

LaTeX Installation
computers are awful
faster pussycat
LaTeX

Path integral formulations of SDEs
dynamical systems
probability
SDEs
statmech
stochastic processes
time series

Cats
fit
health

ML benchmarks and their pitfalls
economics
game theory
how do science
incentive mechanisms
institutions
machine learning
neural nets
statistics
Differentiable model selection
functional analysis
how do science
model selection
optimization
statmech
Prediction processes
dynamical systems
energy
mind
probability
statistics
statmech

Dynamical systems via Koopman operators
dynamical systems
Hilbert space
kernel tricks
regression
signal processing
statistics
time series

Kernel zoo
Hilbert space
kernel tricks
metrics
signal processing
statistics
stochastic processes
Colour
making things
mind
perception
sparser than thou

Generically approximating probability distributions
approximation
functional analysis
metrics
model selection
optimization
probability
statistics

Assorted laws and paradoxes
economics
language
mind

Determinantal point processes
linear algebra
Monte Carlo
point processes

Technopoetics
language
making things
mind

Log concave distributions
Bayes
estimator distribution
Markov processes
Monte Carlo
probabilistic algorithms
probability

Statistics, computational complexity thereof
machine learning
statistics
Matrix measure concentration inequalities and bounds
dynamical systems
functional analysis
high d
linear algebra
model selection
probability
stochastic processes

Measure concentration inequalities
approximation
dynamical systems
functional analysis
measure
metrics
model selection
probability
stochastic processes

Mind reading by computer
life
machine learning
mind
neuron
photon choreography
statistics

Memory in machine learning
language
machine learning
neural nets
NLP

Convolutional Gaussian processes
Gaussian
geometry
Hilbert space
how do science
kernel tricks
machine learning
PDEs
physics
regression
signal processing
spatial
statistics
stochastic processes
time series

Random fields as stochastic differential equations
Bayes
dynamical systems
edge computing
linear algebra
probability
signal processing
state space models
statistics
stochastic processes
time series
Stochastic processes on manifolds
Gaussian
geometry
Hilbert space
how do science
kernel tricks
machine learning
PDEs
physics
regression
signal processing
spatial
statistics
stochastic processes
time series
uncertainty

Learning covariance functions
Hilbert space
kernel tricks
metrics
signal processing
statistics
stochastic processes

Frames and Riesz bases
functional analysis
Hilbert space
linear algebra
probability
signal processing
sparser than thou

Stability in linear dynamical systems
dynamical systems
functional analysis
Hilbert space
probability
statistics

Chaos expansions
Bayes
Hilbert space
Lévy processes
Markov processes
probability
SDEs
stochastic processes

Office software
computers are awful
faster pussycat
number crunching
office
UI

Make your own podcast why not
content
music

Online collaboration
academe
communicating
computers are awful together
distributed
diy
mind
UI
Integral transforms
functional analysis
Hilbert space
linear algebra
signal processing
sparser than thou
Feynman-Kac formulae
Bayes
Monte Carlo
probabilistic algorithms
probability
state space models
statistics
swarm
time series

Warping of stationary stochastic processes
Hilbert space
kernel tricks
metrics
signal processing
statistics
stochastic processes
Miscellaneous nonstationary kernels
Hilbert space
kernel tricks
metrics
signal processing
statistics
stochastic processes
Running a secure server
computers are awful
computers are awful together
confidentiality
security

Bayesians vs frequentists
how do science
statistics
Auditory features
computers are awful
machine learning
machine listening
making things
music
signal processing

Browse the internet for me
browser
computers are awful together
confidentiality
diy
doing internet
faster pussycat

Positive (semi-)definite kernels
Hilbert space
kernel tricks
metrics
signal processing
statistics
stochastic processes

Why does deep learning work?
machine learning
neural nets
optimization
statmech

Generative adversarial networks
adversarial
AI
Bregman
game theory
generative
learning
likelihood free
Monte Carlo
optimization
probability

Garbled highlights from NeurIPS 2020
neural nets
statistics
Sun protection
diy
fashion
gear
health

Random embeddings and hashing
feature construction
functional analysis
linear algebra
probabilistic algorithms
probability
sparser than thou
statistics

Randomised regression
feature construction
functional analysis
linear algebra
probabilistic algorithms
probability
sparser than thou
spheres
statistics
Distributed consistency
computers are awful
computers are awful together
concurrency hell
premature optimization

Distribution regression
functional analysis
metrics
optimization
statistics

Probabilistic spectral analysis
Bayes
dynamical systems
linear algebra
probability
sciml
signal processing
state space models
statistics
stochastic processes
time series

Tensor regression
algebra
Hilbert space
Julia arrays
computers are awful
julia
number crunching
premature optimization
Observability and sensitivity in learning dynamical systems
dynamical systems
Markov processes
regression
signal processing
statistics
statmech
time series
Weighted data in statistics
estimator distribution
functional analysis
linear algebra
model selection
probability
signal processing
sparser than thou
statistics
uncertainty
Chromium browsers
computers are awful
computers are awful together
faster pussycat
standards
UI

Markov Chain Monte Carlo methods
Bayes
estimator distribution
Markov processes
Monte Carlo
probabilistic algorithms
probability
Julia, testing and packaging
computers are awful
julia
premature optimization
standards
GP inducing variables
algebra
approximation
Gaussian
generative
graphical models
Hilbert space
kernel tricks
machine learning
networks
optimization
probability
statistics

GP inducing features
algebra
approximation
Gaussian
generative
graphical models
Hilbert space
kernel tricks
machine learning
networks
optimization
probability
spheres
statistics
Localized Gaussian processes
algebra
approximation
Gaussian
generative
graphical models
Hilbert space
kernel tricks
machine learning
networks
optimization
probability
statistics
Efficient factoring of GP likelihoods
algebra
approximation
Gaussian
generative
graphical models
Hilbert space
kernel tricks
machine learning
networks
optimization
probability
statistics
Audiovisuals
computers are awful
generative art
machine learning
machine listening
machine vision
making things
music
photon choreography
signal processing
UI
Bandit problems
bandit problems
control
decision theory
signal processing
stochastic processes
stringology

Julia IO
computers are awful
julia
Agtech/Agritech
computers are awful together
confidentiality
ecology
food
money
technology

Alternative file managers
computers are awful
diy
POSIX
UI

Sparse model selection
estimator distribution
functional analysis
high d
linear algebra
model selection
probability
signal processing
sparser than thou
statistics

AutoML
functional analysis
how do science
model selection
optimization
statmech
Monte Carlo optimisation
Bayes
density
estimator distribution
Monte Carlo
probabilistic algorithms
probability
statistics
statmech
stochastic processes

Splitting simulation
Bayes
density
Monte Carlo
probabilistic algorithms
probability
risk
time series

Webcams
communicating
computers are awful
photon choreography

Quantitative risk measurement
crisis
density
economics
probability
risk
statistics


Big data ML best practice
computers are awful
machine learning
neural nets
Graph computation
compsci
networks
Filter design, linear
dynamical systems
Hilbert space
signal processing
statistics
time series

Gaussian process quantile regression
Hilbert space
kernel tricks
ordinal
regression
risk
Independence, conditional, statistical
algebra
functional analysis
graphical models
metrics
model selection
networks
probability
statistics

Statistics of spatio-temporal processes
Gaussian
Hilbert space
kernel tricks
spatial
statistics
stochastic processes
time series

Data dimensionality reduction
classification
compsci
feature construction
functional analysis
information
linear algebra
machine learning
networks
neural nets
probability
sparser than thou
statistics
topology

Variational autoencoders
approximation
Bayes
generative
optimization
probabilistic algorithms
probability
statistics
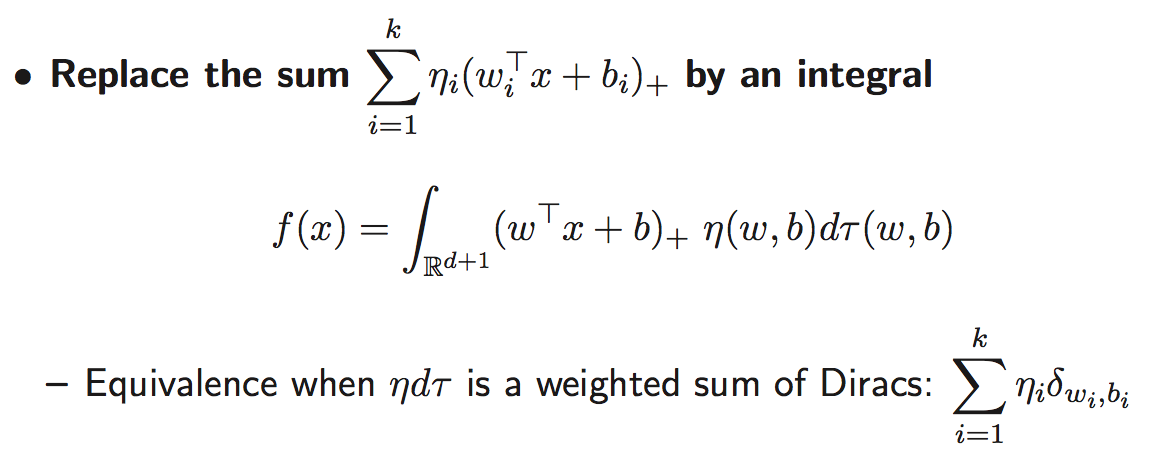
Neural nets
machine learning
neural nets
optimization

Live looping music software
making things
music
signal processing
Causal graphical model reading group 2020
algebra
how do science
machine learning
networks
probability
statistics
Causal Bayesian networks
algebra
graphical models
how do science
machine learning
networks
probability
statistics
Emulators and surrogate models via ML
feature construction
functional analysis
linear algebra
machine learning
networks
neural nets
PDEs
physics
probability
sparser than thou
statistics
statmech
surrogate
Ethnomusicology in the technologised, globalised world
culture
information provenance
making things
music
technology
Mathematics of textiles
algebra
topology

Bushfire models
geometry
how do science
machine learning
physics
statmech
straya

Minimum description length
Bayes
information
model selection
statistics
stringology


Plotting stuff in julia
computers are awful
dataviz
julia
photon choreography
statistics
Combinatorics of note
compsci
Monte Carlo
probabilistic algorithms
pseudorandomness
stringology

Networking stunts
computers are awful
computers are awful together
macos

Citation management
academe
collective knowledge
computers are awful
faster pussycat
how do science
workflow

Low code development
browser
computers are awful
confidentiality
faster pussycat

Task launchers
computers are awful
faster pussycat
Financial markets
economics
incentive mechanisms
institutions
markets
money
wonk

Economics of insurgence
cooperation
democracy
distributed
economics
game theory
networks
squad
wonk
Debugging, profiling and accelerating Julia code
computers are awful
julia
premature optimization
Learning of manifolds
feature construction
functional analysis
machine learning
networks
neural nets
statistics
topology

Model complexity penalties
estimator distribution
information
likelihood
model selection
statistics
Firms: What is WITH you?
cooperation
economics
institutions
mechanism design
mind

Deep fakery
collective knowledge
economics
game theory
incentive mechanisms
machine learning
neural nets
photon choreography

Encrypting, signing, verifying stuff
computers are awful
confidentiality
cryptography

Productivity schemes
economics
faster pussycat
game theory
institutions
mind

Installing Julia
computers are awful
julia

Inference on social graphs
causality
collective knowledge
cooperation
distributed
game theory
networks
social graph
Functional regression
calculus
dynamical systems
functional analysis
Hilbert space
nonparametric
sparser than thou
time series

Long memory time series
model selection
regression
self similar
signal processing
statistics
stochastic processes
time series

Link rot, mitigating
computers are awful
computers are awful together
confidentiality
distributed
diy
economics
How to reduce government spying on you
computers are awful
computers are awful together
confidentiality
wonk

Natural gradient descent
functional analysis
geometry
optimization
statistics
Malliavin calculus
dynamical systems
SDEs
signal processing
stochastic processes
time series
Variational inference
approximation
metrics
optimization
probabilistic algorithms
probability
statistics

Lévy stochastic differential equations
dynamical systems
Hilbert space
SDEs
signal processing
sparser than thou
statistics
stochastic processes
time series
Screen capture and screen casting
diy
making things
Javascript apps
computers are awful
javascript


Directed graphical models
algebra
graphical models
hidden variables
hierarchical models
machine learning
networks
probability
statistics
New-wave jigsaw puzzles
making things
photon choreography

Adaptive Markov Chain Monte Carlo samplers
Bayes
estimator distribution
Markov processes
Monte Carlo
probabilistic algorithms
probability
Tuning an MCMC sampler
Bayes
estimator distribution
Markov processes
Monte Carlo
probabilistic algorithms
probability

Empirical estimation of information
classification
compsci
information
metrics
nonparametric
statistics
statmech
C++
computers are awful
premature optimization
The cross entropy method
Bayes
estimator distribution
Monte Carlo
probabilistic algorithms
probability

Mixture models for density estimation
Bayes
classification
clustering
compsci
convolution
density
information
linear algebra
nonparametric
probability
sparser than thou
statistics

Waste, and the late capitalist industrial metabolism
ecology
economics
sustainability
wonk

Matching and weighting
Bayes
confidentiality
hidden variables
hierarchical models
mind
networks
regression
sociology
statistics
wonk
DIY computer radio
computers are awful together

Garden hacks
diy
sustainability

Supercollider
computers are awful
making things
music
How to reduce criminals spying on you
computers are awful
confidentiality
wonk

Analysis/resynthesis of audio
algebra
generative art
machine learning
machine listening
making things
music
networks
probability
signal processing
statistics

Queueing
count data
probability
statistics
time series

Hygiene, empirical
diy
health
Epidemics
branching
count data
health
life
networks
SDEs
social graph
statistics
stochastic processes
time series
Internet for the occasionally online
computers are awful
computers are awful together
confidentiality
distributed
diy
economics
Teaching computers to write music
buzzword
computers are awful
generative art
machine learning
making things
music
neural nets
Graphic design for the vexed
making things
photon choreography

Nature, nurture and friends
evolution
gene
semantics
The surveillance society
confidentiality
cooperation
incentive mechanisms
institutions
insurgency
policy
straya
the rather superior sort of city
wonk
Encrypted filesystem on linux
computers are awful
POSIX
Order statistics
ordinal
probability
regression
statistics
DIY internet infrastructure
confidentiality
distributed
diy
economics
P2P

Tool discovery
collective knowledge
computers are awful
faster pussycat

Faking being on social media
diy
doing internet
faster pussycat
workflow

Restricted isometry properties
functional analysis
Hilbert space
linear algebra
probability
signal processing
sparser than thou
Diff/merge tools
computers are awful
information provenance
stringology
workflow
Kernel approximation
algebra
functional analysis
Hilbert space
linear algebra
model selection
nonparametric
probabilistic algorithms
probability
signal processing
sparser than thou

Historical English
history
language
Effective sample size
dynamical systems
model selection
Monte Carlo
signal processing
statistics
time series
Bias reduction
estimator distribution
nonparametric
probabilistic algorithms
statistics
Learnable indexes and hashes
approximation
feature construction
geometry
high d
language
linear algebra
machine learning
metrics
networks
neural nets
statistics
topology

Microsoft Azure cloudydoodle numberpants crunchery
compsci
computers are awful
concurrency hell
premature optimization

Selling uncertainty
collective knowledge
economics
how do science
mind
sociology
wonk

Asynchronous Python
computers are awful
concurrency hell
python
Sunda
music
nusantara
place
South East Asia
Sunda
Cepstral transforms and harmonic identification
dynamical systems
Hilbert space
machine listening
music
signal processing
statistics
time series
Yak shaving
faster pussycat
R Shiny
computers are awful
how do science
number crunching
statistics
UI

Random change of time
functional analysis
measure
probability
time series
Branching processes
branching
count data
functional analysis
Lévy processes
point processes
probability
statistics
time series
Digital forensics
computers are awful
information provenance
photon choreography
statistics
Infinitesimal generators
dynamical systems
Lévy processes
Markov processes
probability
SDEs
stochastic processes
Poisson point processes
Lévy processes
point processes
probability
spatial
stochastic processes
Psychoacoustics
making things
mind
music
perception
Differential privacy
confidentiality
statistics
*-omics
buzzword
gene
information provenance
networks
stringology
Learning in adaptive systems
economics
hidden variables
hierarchical models
machine learning
mind
sociology
statistics
wonk
Switching to netlify
communicating
computers are awful together
diy
doing internet
faster pussycat
plain text
UI
workflow

Media metadata management and editing
computers are awful
faster pussycat
making things
music
photon choreography
standards
Wikis
collective knowledge
computers are awful
faster pussycat
information provenance

Esoteric language zoo
compsci
computers are awful
faster pussycat
stringology

Information geometry
functional analysis
geometry
networks
statistics
FFMPEG
computers are awful
music
premature optimization
Hawkes processes
branching
count data
functional analysis
point processes
probability
social graph
statistics
time series
virality
Linux filesystem hacks
computers are awful
POSIX

Controllerism
machine learning
making things
music
real time
UI
![]()
Permanental point processes
linear algebra
Monte Carlo
point processes
Spatial point process and their statistics
spatial
statistics
statmech

Convergence of random variables
dynamical systems
functional analysis
model selection
probability
stochastic processes
Cherchez la martingale
dynamical systems
Hilbert space
linear algebra
probability
SDEs
signal processing
time series
Clojure
compsci
computers are awful
Local and networked UIs in Julia
computers are awful
julia
UI
Audio source separation
algebra
generative art
machine learning
machine listening
making things
music
networks
probability
signal processing
statistics
Trusting information
collective knowledge
confidentiality
game theory
incentive mechanisms
mind
sociology
wonk


Tunings
algebra
machine learning
machine listening
making things
music

Machine listening
computers are awful
java
machine learning
machine listening
making things
music
python
signal processing
Coupling in stochastic process
metrics
probability
statistics
ISMIR 2019
computers are awful
machine learning
machine listening
making things
music
signal processing
Phase retrieval
feature construction
Hilbert space
machine learning
model selection
neural nets
optimization
Audio synthesis in python
computers are awful
generative art
music
UI
Webhooks
computers are awful
faster pussycat

Smartypants cities
buzzword
cooperation
culture
design
diy
economics
housing
incentive mechanisms
institutions
insurgency
making things
policy
spatial
straya
the rather superior sort of city
wonk
Optimal control
bandit problems
Bayes
dynamical systems
linear algebra
optimization
probability
sciml
signal processing
statistics
time series

Generative art, creative coding, procedural design
computers are awful
generative art
making things
music
photon choreography
Undirected graphical models
algebra
graphical models
machine learning
networks
probability
statistics
Gradient descent, Higher order
functional analysis
neural nets
optimization
statmech
Sparse regression
estimator distribution
functional analysis
linear algebra
model selection
probability
signal processing
sparser than thou
statistics

Delays and reverbs for audio processing
dynamical systems
linear algebra
music
regression
signal processing
time series
Frequentist consistency of Bayesian methods
Bayes
how do science
statistics
Discrete time Fourier and related transforms
convolution
functional analysis
Hilbert space
nonparametric
signal processing
sparser than thou
Density estimation
convolution
density
functional analysis
nonparametric
probability
statistics
The tidyverse
computers are awful
number crunching
R
statistics
Bio computing
compsci
life
machine learning
neuron
Zeros of random trigonometric polynomials
control
functional analysis
probability
signal processing
Generalized Galton-Watson processes
branching
count data
probability
time series
Random (element) matrix theory
algebra
functional analysis
geometry
high d
linear algebra
measure
probabilistic algorithms
probability
signal processing
sparser than thou
spheres
Statistical learning theory for time series
Markov processes
model selection
optimization
regression
statistics
stochastic processes
time series

Correlograms
dynamical systems
Hilbert space
linear algebra
signal processing
statistics
time series

Defining dynamics via Gaussian processes
Bayes
dynamical systems
Gaussian
generative
Hilbert space
kernel tricks
linear algebra
probability
sciml
signal processing
state space models
statistics
time series

Representer theorems
approximation
functional analysis
Hilbert space
kernel tricks
metrics
statistics

Network firewalls, routing etc
computers are awful
macos
Sneakernets
computers are awful together
confidentiality
distributed
diy
economics
P2P

Go bag, Sydney edition
crisis
diy
economics
fashion
sustainability

EZ cross-platform apps
computers are awful
javascript

Bayesian model selection
Bayes
information
model selection
statistics

Probability
algebra
functional analysis
probability

Installations (in galleries etc)
computers are awful
diy
making things
Fourier interpolation
feature construction
functional analysis
linear algebra
networks
probability
signal processing
sparser than thou
statistics
Build tools for data science
faster pussycat
premature optimization
Topology, applied to problems I know about
networks
topology

Game complexity
compsci
economics
game theory
incentive mechanisms
markets

Wiener theorem
functional analysis
Hilbert space
optimization
signal processing
stochastic processes
Wacky regression
classification
functional analysis
model selection
nonparametric
optimization
regression
Statistics software
computers are awful
number crunching
statistics


Ordinary differential equations
calculus
functional analysis
Hilbert space
statistics

Hollow states
cooperation
economics
hand wringing
institutions
wonk
Csound
computers are awful
diy
generative art
lua
making things
music

Point processes
branching
point processes
spatial
statmech
Inner product spaces
algebra
functional analysis
Hilbert space
metrics
nonparametric
Javascript
compsci
computers are awful
Dictionaries
language
Nearly sufficient statistics
approximation
estimator distribution
functional analysis
information
linear algebra
metrics
model selection
optimization
probabilistic algorithms
probability
sparser than thou
statistics
uncertainty
Normed spaces
algebra
functional analysis
metrics
nonparametric

Machine vision
computers are awful
machine learning
machine vision
Gesture recognition
machine learning
making things
music
real time
UI
Atom
compsci
computers are awful
faster pussycat
plain text
UI
workflow
Multiple testing
decision theory
high d
how do science
linear algebra
machine learning
model selection
nonparametric
statistics
uncertainty

Sparse stochastic processes identification and sampling
calculus
dynamical systems
geometry
Hilbert space
how do science
Lévy processes
physics
sciml
SDEs
signal processing
statistics
statmech
stochastic processes
time series
uncertainty
Evidential decision theory
agents
economics
game theory
mind
Surviving bash
computers are awful
macos
POSIX
Pattern formation
chemistry
generative art
life
photon choreography
self similar
spatial
statmech
stochastic processes
Field Programmable hardware and ilk
diy
premature optimization

10 years of the Living Thing!
making things
review
Optimisation, combinatorial
functional analysis
optimization
statmech
Serious number crunching on Google Cloud
computers are awful
concurrency hell
premature optimization
Art python
computers are awful
generative art
music
UI

Sundanese music
music
nusantara
South East Asia
Sunda

Submodular functions, maximizing
complexity
compsci
optimization
Facebook messages pro-forma response
computers are awful
confidentiality
diy
wonk
How is foreign filesystem access in macOS awful this week?
computers are awful
macos
Signal processing
dynamical systems
Hilbert space
signal processing
statistics
time series

Matlab
computers are awful
linear algebra
signal processing

“Business Leadership”
incentive mechanisms
institutions
mind
wonk
Rare-event-conditional estimation
Bayes
estimator distribution
Monte Carlo
probabilistic algorithms
probability
Quantum probability
Hilbert space
probability
quantum
Behavioural economics
bounded compute
economics
mind
sociology
Post-selection inference
information
model selection
statistics
Model/hyperparameter selection
information
model selection
statistics
Gradient descent, continuous, primal/dual formulations.
functional analysis
optimization
statmech
Quantum-probabilistic graphical models
graphical models
machine learning
networks
probability
quantum
statistics

Warping and registration problems
functional analysis
measure
probability
time series
Our microbiome
adaptive
ecology
food
gene
Australian English
language
straya
In Wild Air
making things
review
Chinese language
china
language
Lagrangian mechanics
functional analysis
optimization
physics
Stochastic processes and fields
probability
stochastic processes
time series

Compressed sensing and sampling
functional analysis
linear algebra
model selection
probabilistic algorithms
probability
signal processing
sparser than thou

Thermodynamics of life
buzzword
compsci
life
statmech
time series
Marketing psychology
Bayes
hidden variables
hierarchical models
machine learning
networks
probability
regression
statistics
wonk
Linear and least-squares estimation of point processes
branching
spatial
Sustainability
collective knowledge
crisis
economics
incentive mechanisms
life
sustainability
wonk

Financial stability
crisis
economics
incentive mechanisms
institutions
markets
money
risk
Uncertainty principles
functional analysis
Hilbert space
probability
![]()
Granger causation/Transfer Entropy
information
statistics
stringology
time series
Game theory
bounded compute
cooperation
economics
game theory
incentive mechanisms
mind
Justice
economics
ethics
mind
Musical metrics and manifolds
algebra
machine learning
making things
mind
music
perception
How is deep learning on Amazon EC2 awful this week?
computers are awful
concurrency hell
premature optimization
Serious number crunching on Amazon Web Services
computers are awful
concurrency hell
premature optimization
How is Google Cloud ML awful this week?
computers are awful
concurrency hell
premature optimization
Scala
computers are awful
premature optimization
Functional equations
algebra
convolution
functional analysis
Hilbert space
Fractional Brownian motion
probability
self similar
statistics
stochastic processes
time series

Quasi Monte Carlo
concurrency hell
Monte Carlo
probabilistic algorithms
pseudorandomness
Metric entropy
approximation
functional analysis
measure
probability
statistics
Garbled highlights from NIPS 2016
neural nets
statistics
Synestizer
javascript
machine vision
making things
music
portable
UI

Concatenative synthesis
Hilbert space
machine listening
making things
music
Javascript reactive programming and streams
computers are awful
concurrency hell
javascript
UI
Genetic algorithms
computers are awful
evolution
machine learning
Special functions
physics
probability
statistics
Greatest hits
computers are awful
machine learning
making things
music
signal processing
The simplex
classification
metrics
probability
statistics
UNSW Stats reading group 2016 - Causal DAGs
machine learning
networks
probability
statistics
Inference from disorder
compsci
machine learning
networks
probability
pseudorandomness
statistics
Maximum likelihood inference
likelihood
optimization
probability
statistics
Distributed statistica inference
computers are awful
concurrency hell
distributed
optimization
premature optimization
statmech
Stability (in learning)
estimator distribution
model selection
statistics
uncertainty

Fast multipole methods
Hilbert space
premature optimization
Women in electronic and popular music
diy
music
wonk
Kernel density estimators
convolution
nonparametric
statistics

Statistical learning theory
approximation
functional analysis
machine learning
measure
metrics
model selection
optimization
probability
statmech
Change of probability measure
density
measure
probability
time series
Surviving macOS server
computers are awful
macos

Blind deconvolution
convolution
functional analysis
linear algebra
probability
signal processing
sparser than thou
statistics
Dynamical systems
calculus
dynamical systems
geometry
Hilbert space
how do science
Lévy processes
machine learning
neural nets
PDEs
physics
regression
sciml
SDEs
signal processing
statistics
statmech
stochastic processes
sync
time series
uncertainty
Maximum processes
probability
stochastic processes
Text processing
music
NLP
search
semantics
stringology

Rummaging in string bags
music
search
semantics
stringology
“Approximate models”
statistics

Function approximation and interpolation
convolution
functional analysis
Hilbert space
nonparametric
signal processing
sparser than thou

Function approximation and interpolation
convolution
functional analysis
Hilbert space
nonparametric
signal processing
sparser than thou
Clustering
Bayes
clustering
convolution
density
feature construction
networks
nonparametric
probability
sparser than thou
statistics

Iterated function systems
functional analysis
grammar
life
making things
photon choreography
self similar
Curved exponential families
geometry
probability
statistics
Category theory
algebra
compsci
Expectation maximisation
algebra
graphical models
hidden variables
hierarchical models
networks
optimization
probabilistic algorithms
probability
statistics
Deconvolution
convolution
density
functional analysis
linear algebra
nonparametric
probability
signal processing
sparser than thou
statistics
Bahasa Indonesia
language
nusantara
Thermodynamics
physics
statmech
Message queues
computers are awful
computers are awful together
concurrency hell
premature optimization

Art LISP
compsci
computers are awful
making things
Count time series models
count data
probability
regression
statistics
time series
Coarse graining
algebra
Bayes
machine learning
networks
physics
sciml
snarks
statmech
surrogate
High frequency time series estimation
finance
regression
statistics
stochastic processes
time series

Hidden variable formalisms in quantum mechanics
how do science
probability
quantum
Visuals
computers are awful
photon choreography
Parking sun
generative art
making things
music
Pattern machine
buzzword
computers are awful
generative art
machine learning
making things
music
neural nets
Statistical mechanics
economics
game theory
statmech
Ensemble Tikoro collaboration
making things
music
nusantara
South East Asia
Sunda

Scarce urban resources
culture
design
diy
the rather superior sort of city
Spamularity
AI
confidentiality

How to make crazy experiment on sound design (sic)
diy
music
signal processing
Islam
religion
Earthquakes
branching
PDEs
physics
statmech
Stream processing and reactive programming
computers are awful
concurrency hell
premature optimization
signal processing
stringology

Copula functions
density
probability
risk
statistics
Sigma algebras, probability spaces, measure theory
algebra
functional analysis
networks
probability
time series
Altruism
cooperation
economics
snarks
wonk
Geometry of fitness landscapes
evolution
geometry
optimization
topology
Architecture (doing it)
design
the rather superior sort of city

Normal accidents
adaptive
cooperation
culture
economics
engineering
ethics
incentive mechanisms
institutions
risk
wonk
Artificial chemistry
grammar
stringology
time series
Sparse regression for inhomogeneous Hawkes processes
count data
regression
sparser than thou
time series
Complexity
statistics
statmech
Mixing and mastering for dummies
computers are awful
diy
music
Microbial Ecology
adaptive
ecology
gene
life
Red Wine Headache
drugs
health
New media art
computers are awful
generative art
making things
Computational mechanics
compsci
information
pseudorandomness
statistics
statmech
stringology
Algebra I would like to learn
algebra
stringology
Flocking
distributed
statmech
swarm
Indonesian food
food
nusantara
Computational complexity
complexity
compsci
pseudorandomness
Disruptive technology
economics
technology
Dialects
language
Pure
computers are awful
Research proposal: Grammars of music
language
project
Time machine 2012
making things
review
Dorkbot group show 2012
making things
review
Macroeconomics
economics
Configuration space of the economy
economics
geometry
topology
Morandini and Blamey
making things
review
Niche construction
evolution
Dorkbot group show 2011
making things
review
Econophysics
buzzword
distributed
economics
statmech
wonk
Honours thesis
economics
project
wonk

Feral
making things
music
project
Simulation for the social sciences
sociology
statmech
The after party for the American Century
making things
review

SXSW from the gutter
making things
review
Transmediale 2010
making things
review
The discreet charm of the bourgeoisie robot
making things
review
robots
Jakarta Biennale 2009 (Realtime Magazine)
making things
review
Jakarta Biennale 2009 (Sentap! Magazine)
making things
review
robots
Dancing machine
making things
review
robots
No matching items